Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- How to delay a new job run after job
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-19-2023 08:01 PM
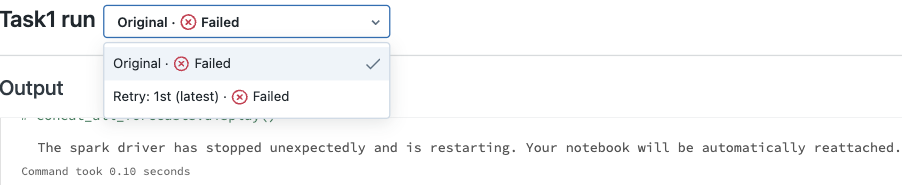
I have a daily job run that occasionally fails with the error: The spark driver has stopped unexpectedly and is restarting. Your notebook will be automatically reattached. After I get the notification that this job failed on schedule, I manually run the job and it runs successfully. This article states that it may fail due to using collect or a shared cluster (although this is the only job that runs on the shared cluster at the scheduled time). Below is portion of the code inside the cell that throws the driver error.
for forecast_id in weekly_id_list:
LOGGER.info(f"Get forecasts from {forecast_id}")
# Get forecast_date of the forecast_id
query1 = (f"SELECT F.forecast_date FROM cosmosCatalog.{cosmos_database_name}.Forecasts F WHERE F.id = '{forecast_id}';")
forecast_date = spark.sql(query1).collect()[0][0]When it fails due to spark driver issue, it automatically do a retry and throw a new error: Library installation failed for library due to user error for pypi {package: "pandas"} . I think databricks already has pandas installed in the cluster, so I don't think I will need to install pandas again, but my assumption is that it'll throw the same error with other packages because it stems from the driver being recently restarted or terminated in the Original run.
So I was wondering if there is a way to define a gap (sleep time) between the original run and the retrial run so that I don't get a library installation error being thrown from the driver being recently restarted or terminated.

Labels:
- Labels:
-
Job
-
Library Installation


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-17-2023 01:16 PM
According to this documentation, you can specify the wait time between the "start" of the first run and the retry start time.
3 REPLIES 3
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-25-2023 12:03 AM
@Jay Yang :
Yes, you can add a sleep time between the original run and the retrial run to avoid the library installation error due to the driver being recently restarted or terminated. Here's an example of how you can modify your code to add a sleep time:
import time
for forecast_id in weekly_id_list:
LOGGER.info(f"Get forecasts from {forecast_id}")
# Get forecast_date of the forecast_id
query1 = (f"SELECT F.forecast_date FROM cosmosCatalog.{cosmos_database_name}.Forecasts F WHERE F.id = '{forecast_id}';")
try:
forecast_date = spark.sql(query1).collect()[0][0]
except:
# If the driver fails, sleep for 5 seconds and try again
time.sleep(5)
forecast_date = spark.sql(query1).collect()[0][0]In this example, the try block attempts to collect the forecast date as usual. If it encounters an error due to the driver being recently restarted or terminated, it will sleep for 5 seconds before attempting to collect the forecast date again. You can adjust the sleep time as needed.
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-26-2023 11:31 PM
Hi @Jay Yang
Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help.
We'd love to hear from you.
Thanks!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-17-2023 01:16 PM
According to this documentation, you can specify the wait time between the "start" of the first run and the retry start time.
Announcements





{kind=link}
{kind=link}
Related Content
- SQL Warehouse stuck on "Cluster Start-up Delayed" in Data Engineering
- SQL Warehouse stuck on "Cluster Start-up Delayed in Data Engineering
- Is Databricks AI/BI Genie worth it if we already have Power BI or Tableau? in Data Engineering
- Best Compute Option for Near-Real-Time Databricks API Ingestion Pipeline in Data Engineering
- Newly added workspace users do not appear immediately in WorkspaceClient().users.list() or SCIM API in Administration & Architecture