Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Method iterableAsScalaIterable does not exist Pyde...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-28-2022 03:06 AM
Hello,
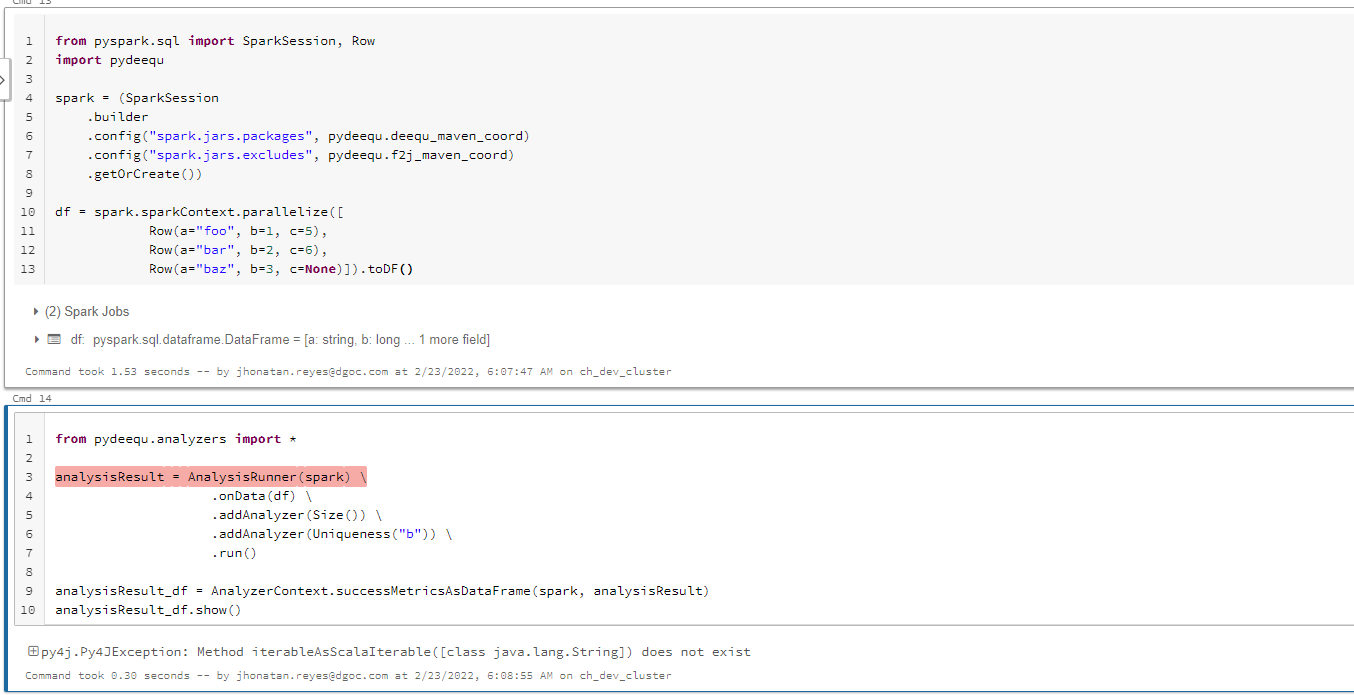
I'm using Databricks and pydeequ to build a QA step in structured streaming.
One of the Analyzers that I need to use is the Uniqueness.
If I try to add another one like Completeness, work properly, but if y add the Uniqueness I get an error:
py4j.Py4JException: Method iterableAsScalaIterable([class java.lang.String]) does not existLog:
Py4JError Traceback (most recent call last)
<[command-1299007449178928]()> in <module>
1 from pydeequ.analyzers import *
2
----> 3 analysisResult = AnalysisRunner(spark) \
4 .onData(df) \
5 .addAnalyzer(Size()) \
/local_disk0/.ephemeral_nfs/envs/pythonEnv-3e8b052e-7811-4908-bcc3-79a52e659d2d/lib/python3.8/site-packages/pydeequ/analyzers.py in addAnalyzer(self, analyzer)
132 """
133 analyzer._set_jvm(self._jvm)
--> 134 _analyzer_jvm = analyzer._analyzer_jvm
135 self._AnalysisRunBuilder.addAnalyzer(_analyzer_jvm)
136 return self
/local_disk0/.ephemeral_nfs/envs/pythonEnv-3e8b052e-7811-4908-bcc3-79a52e659d2d/lib/python3.8/site-packages/pydeequ/analyzers.py in _analyzer_jvm(self)
773 """
774 return self._deequAnalyzers.Uniqueness(
--> 775 to_scala_seq(self._jvm, self.columns), self._jvm.scala.Option.apply(self.where)
776 )
777
/local_disk0/.ephemeral_nfs/envs/pythonEnv-3e8b052e-7811-4908-bcc3-79a52e659d2d/lib/python3.8/site-packages/pydeequ/scala_utils.py in to_scala_seq(jvm, iterable)
77 Scala sequence
78 """
---> 79 return jvm.scala.collection.JavaConversions.iterableAsScalaIterable(iterable).toSeq()
80
81
/databricks/spark/python/lib/py4j-0.10.9.1-src.zip/py4j/java_gateway.py in __call__(self, *args)
1302
1303 answer = self.gateway_client.send_command(command)
-> 1304 return_value = get_return_value(
1305 answer, self.gateway_client, self.target_id, self.name)
1306
/databricks/spark/python/pyspark/sql/utils.py in deco(*a, **kw)
115 def deco(*a, **kw):
116 try:
--> 117 return f(*a, **kw)
118 except py4j.protocol.Py4JJavaError as e:
119 converted = convert_exception(e.java_exception)
/databricks/spark/python/lib/py4j-0.10.9.1-src.zip/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name)
328 format(target_id, ".", name), value)
329 else:
--> 330 raise Py4JError(
331 "An error occurred while calling {0}{1}{2}. Trace:\n{3}\n".
332 format(target_id, ".", name, value))
Py4JError: An error occurred while calling z:scala.collection.JavaConversions.iterableAsScalaIterable. Trace:
py4j.Py4JException: Method iterableAsScalaIterable([class java.lang.String]) does not exist
at py4j.reflection.ReflectionEngine.getMethod(ReflectionEngine.java:341)
at py4j.reflection.ReflectionEngine.getMethod(ReflectionEngine.java:362)
at py4j.Gateway.invoke(Gateway.java:289)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:251)
at java.lang.Thread.run(Thread.java:748)To Reproduce
I'm using the example provided on the main page:


I'm using this version of:
Databricks:

Thanks
Labels:
- Labels:
-
Method


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-28-2022 04:57 AM
I think it is because you did not attach the libraries to the cluster.
When you work with a notebook, the sparksession is already created.
To add libraries, you should install them on the cluster (in the compute tab) using f.e. pypi/maven etc.
4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-28-2022 04:57 AM
I think it is because you did not attach the libraries to the cluster.
When you work with a notebook, the sparksession is already created.
To add libraries, you should install them on the cluster (in the compute tab) using f.e. pypi/maven etc.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-28-2022 05:09 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-28-2022 05:15 AM
ok can you try again without creating a sparksession?
It could also be pydeequ which is imcompatible, I have never used it.
But first let's try without the sparksession part.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-11-2022 01:53 PM
Hi @Jhonatan Reyes ,
Just checking if you still need help on this issue? did @Werner Stinckens 's response helped? if it did, please mark it as best response.





{kind=link}
{kind=link}
{kind=link}
{kind=link}