Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Problems with pandas.read_parquet() and path
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Problems with pandas.read_parquet() and path
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-30-2022 11:20 AM
I am doing the "Data Engineering with Databricks V2" learning path.
I cannot run "DE 4.2 - Providing Options for External Sources", as the first code cell does not run successful:
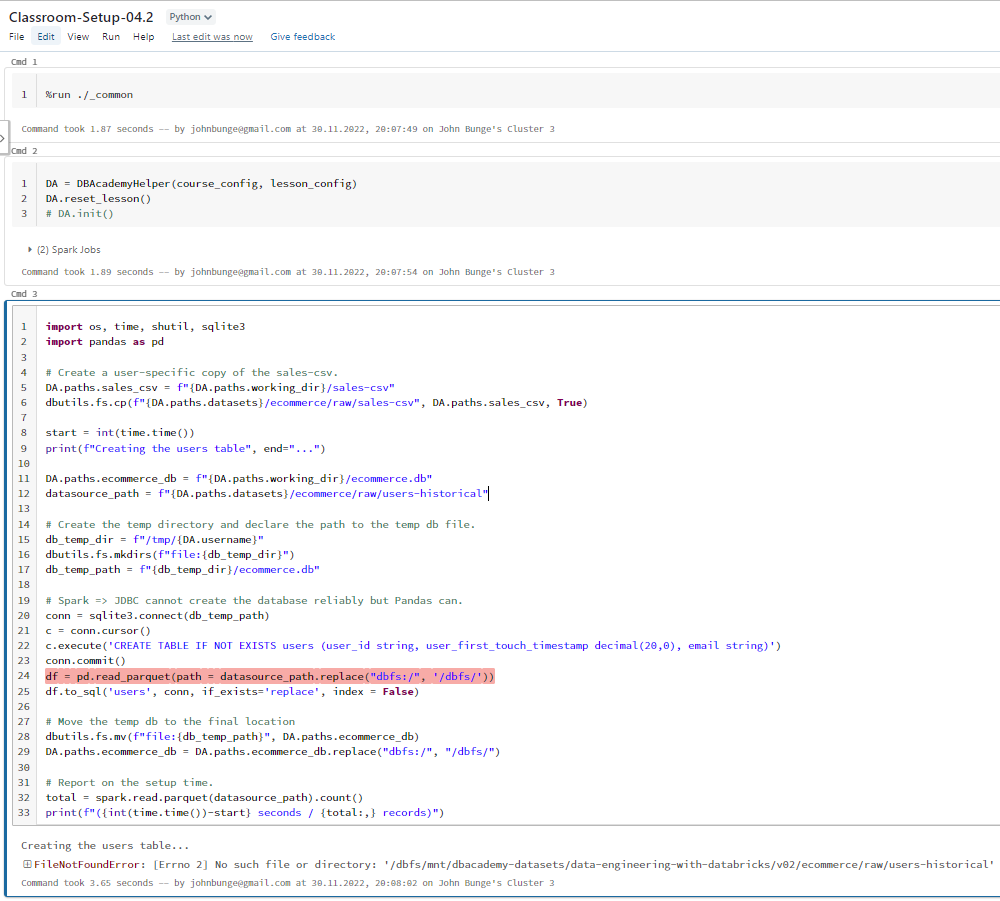
%run ../Includes/Classroom-Setup-04.2Screenshot 1:

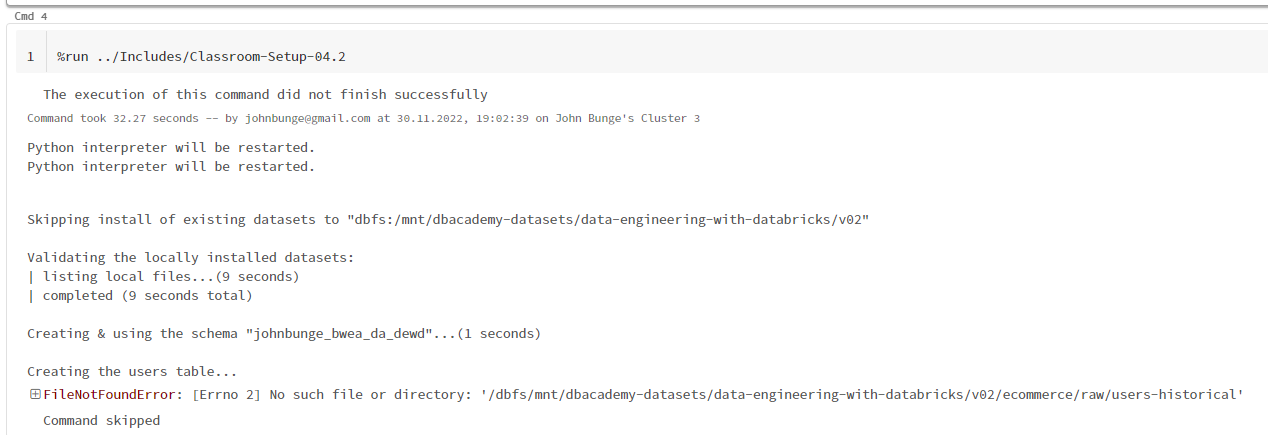
Inside the setup notebook, the code crashes at the following command (see screenshot 2):
df = pd.read_parquet(path = datasource_path.replace("dbfs:/", '/dbfs/'))The error message is:
FileNotFoundError: [Errno 2] No such file or directory: '/dbfs/mnt/dbacademy-datasets/data-engineering-with-databricks/v02/ecommerce/raw/users-historical'
Screenshot 2:
")
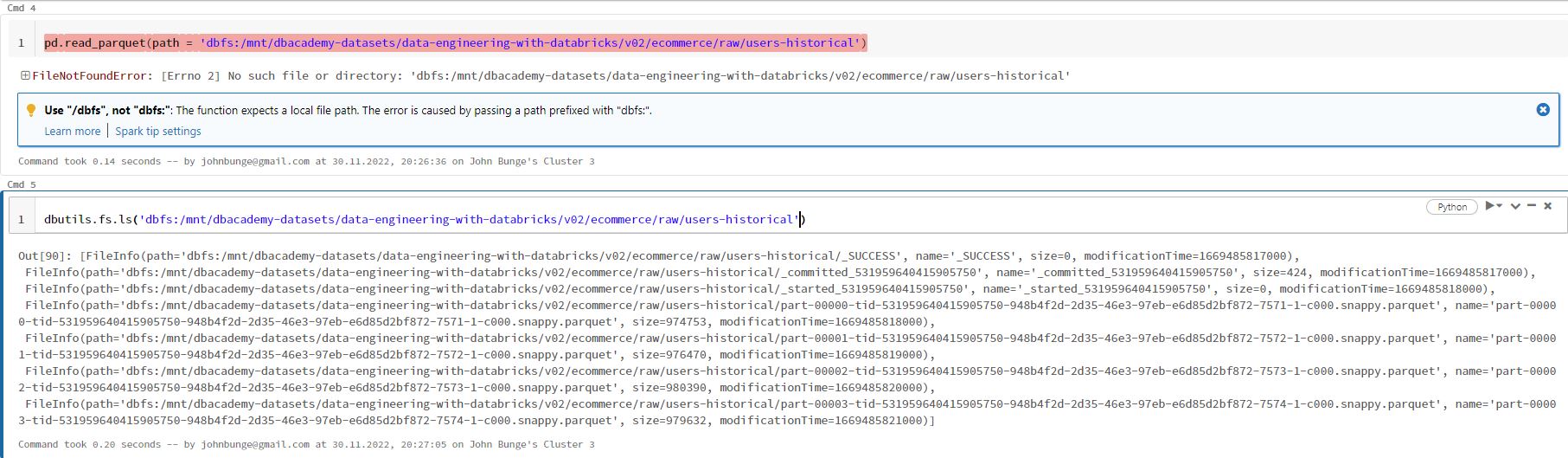
There seems to be an issue with the path, even though it actually exists:
Screenshot 3:

I played around a little with the path specification, but nothing helped:
Screenshot 4:

Labels:
- Labels:
-
Databricks V2


16 REPLIES 16
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-30-2022 11:42 AM
Hi @John B
Can you please try by removing the dbfs and starting with /mnt only.
Also, if this does not work, can you please upload that notebooks DBC archive, so that I would be able to check the details.
Cheers..
Uma Mahesh D
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-16-2022 03:47 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-30-2022 11:54 AM
Also @John B
Assuming this is an old training course, check the same using a community cluster with DBR version less than 7. Some old training courses mount points are disabled in DBR 7+.
Cheers...
Uma Mahesh D
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-03-2022 12:22 AM
@John B
Did your issue get resolved?
If not through the above methods, do ping the fix you did.
Cheers..
Uma Mahesh D
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-16-2022 04:33 AM
@Uma Maheswara Rao Desula I solved the issue using ss2's suggestion (see below). After reading in a Spark DataFrame I converted it into a pandas DataFrame using the ToPandas() method.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-16-2022 03:35 AM
Hi!
I can only use Runtime 7.3, 9.1., ..., 12.0. Minimum is 7.3. I am using DBR commnunity edition.
Br.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-03-2022 07:14 PM
Can u try like this.spark.read.parquet("dbfs:/mnt/.......")
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-16-2022 03:58 AM
Hi @S S
Reading in the file was successful. However, I got a pyspark.sql.dataframe.DataFrame object. This is not the same as a pandas DataFrame, right?
Br.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-16-2022 07:04 AM
Hey @S S ,
I can understand your issue
so to solve this import that DBC file and instead of question one there will be a folder for all solutions so explore solution one it will work.
Please upvote if you got some hint from my answer
Thanks
Aviral Bhardwaj
AviralBhardwaj
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-29-2023 08:11 AM
Hello All,
I am getting the exact issue as motioned in the first pot here. I have tried all the solutions listed: -
- Changing DBR to 7.3: Gave other errors related to libraries not present in that DBR version
- Using spark.read.parquet: This is giving "AnalysisException: Unable to infer schema for Parquet. It must be specified manually." error. I have checked the parquet files exists in that location and they are not empty.
- Exploring solutions folder: It is giving the same errors.
Any ideas what else I can try please.
Thanks.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-04-2024 01:35 AM
I used spark.read.parquet and then convereted that to pandas dataframe and it worked for me.
Upvote if it helped you.

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-28-2024 07:37 AM

Worked for me too! Thanks
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-29-2024 06:38 PM
Thanks it helped.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-02-2024 06:34 AM
Thanks for sharing this helped me too 🤖
Announcements





.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Clarification on Auto Loader Managed File Events with Unity Catalog Managed Volumes in Data Engineering
- Clarification on Auto Loader Managed File Events with Unity Catalog Managed Volumes in Administration & Architecture
- Did something change with the setup of Unity Catalogs? in Administration & Architecture
- Free Edition CrossValidator not working because of internal caching in Machine Learning
- Getting 'Unauthorized Access' when Serverless compute is trying to read s3 bucket data in Data Engineering