Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: SQLServerException: deadlock
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-24-2022 11:30 AM
I'm using databricks to connect to a SQL managed instance via JDBC. SQL operations I need to perform include DELETE, UPDATE, and simple read and write. Since spark syntax only handles simple read and write, I had to open SQL connection using Scala and perform DELETE and UPDATE queries.
Here's a sample scala code I use to execute delete queries:
val connection = DriverManager.getConnection(jdbcUrl, jdbcUsername, jdbcPassword)
val statement = connection.createStatement()
val queryStr = "DELETE FROM SAMPLE"
val res = stmt.execute(queryStr)
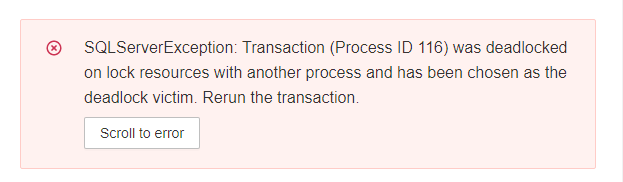
connection.close()These lines work perfectly fine if I run one notebook at a time. However, when I run several notebooks in parallel, I can get into deadlock issues (see below)



1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-25-2022 07:29 AM
the issue is not your code but the fact that you run the queries in parallel. The SQL server database cannot handle that for some reason.
f.e. one notebook run is doing an update while another wants to delete that record.
6 REPLIES 6
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-25-2022 05:39 AM
this is not a spark error but purely the database.
There are tons of articles online on how to prevent deadlocks, but there is no single solution for this.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-25-2022 07:25 AM
I'm not a fluent Scala user. Do you happen to know one solution that deals with JDBC in Scala?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-25-2022 07:29 AM
the issue is not your code but the fact that you run the queries in parallel. The SQL server database cannot handle that for some reason.
f.e. one notebook run is doing an update while another wants to delete that record.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-25-2022 07:52 AM
Got it! Thank you so much! It looks like I can use error handling to rerun the deadlock victim until it works. Thanks for pointing me to the right direction!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2024 06:14 AM
You have manged time and stp step need person operation so deadlock can avoided. This is purly database proplem which can avoid in making time difference or short transcation in database operation.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-21-2024 04:56 AM - edited 10-21-2024 04:58 AM
@swzzzsw
Since you are performing database operations, to reduce the chances of deadlocks, make sure to wrap your SQL operations inside transactions using commit and rollback.
Another approachs to consider is adding retry logic or using Isolation Levels. For more information, refer to the Databricks documentation on isolation levels ( Isolation Levels Documentation )
Announcements





{kind=link}
Related Content
- Extract SQL function in SQL Server federated database in Data Engineering
- deadlock occurs with use statement in Data Engineering
- Error filtering by datetime Lakehouse Federated SQL Server table in Data Engineering
- Remote SQL Server Instance Connection using JDBC in Data Engineering
- Getting connection reset issue while connecting to a SQL server in Data Engineering