Our use case is to "clean up" column names (remove spaces, etc) on ingestion of CSV data using the Delta Live Table capability. We desire to use the schema inference capability during ingestion so schema specification (up front) will not be happening.
Explored usage of .withColumnRenamed for offending columns but quickly became intractable as column count is over 100 now.
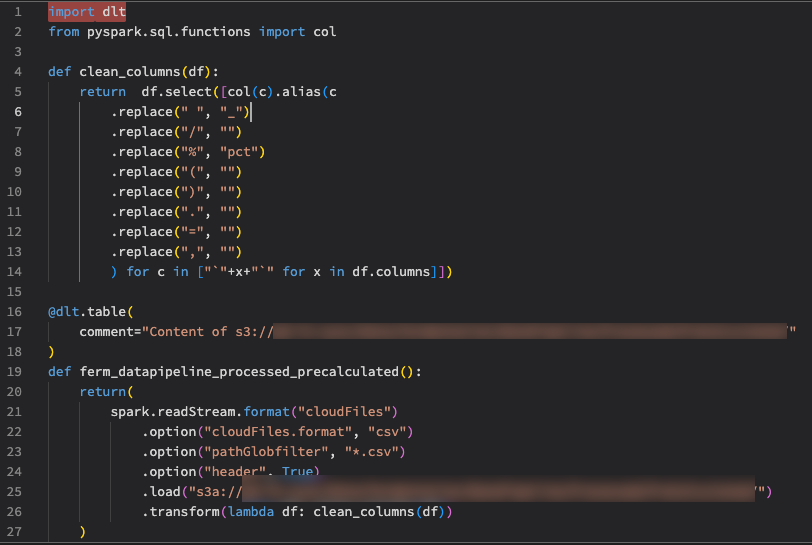
After some research we settled on defining a UDF for the use case that will .replace characters we want to remove on column names. The UDF uses python list comprehension; however, the call to df.columns does not return the lift of column names as expected.
File "/databricks/spark/python/pyspark/sql/column.py", line 87, in _to_seq
cols = [converter(c) for c in cols]
File "/databricks/spark/python/pyspark/sql/column.py", line 87, in <listcomp>
cols = [converter(c) for c in cols]
File "/databricks/spark/python/pyspark/sql/column.py", line 66, in _to_java_column
raise TypeError(
TypeError: Invalid argument, not a string or column: DataFrame[Run #: string, Tank #: string, ...
Here is the implementation:
--
import dlt
from pyspark.sql.functions import col as my_col
from pyspark.sql.functions import udf as my_udf
@my_udf
def clean_columns(df):
return df.select([my_col(x).alias(x
.replace(" ", "_")
.replace("/", "")
.replace("%", "pct")
.replace("(", "")
.replace(")", "")
) for x in df.columns])
@dlt.table(
comment="test"
)
def test_rawzone_data():
return(
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "csv")
.option("pathGlobfilter", "*.csv")
.option("header", True)
.load("s3://obfuscated-of-course/etc/etc/Pipeline//")
.transform(clean_columns)
)
The transform function invokes "with context" and passes the DataFrame but the Type isn't resolving. Namespace collisions? Anyone have recommendations for improvements to the UDF or pursuing a different approach?
Thank you for any pointers.








{kind=link}