Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Governance
Join discussions on data governance practices, compliance, and security within the Databricks Community. Exchange strategies and insights to ensure data integrity and regulatory compliance.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Governance
- Re: Running Stored Procedures on a Multi-node/ Sha...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Running Stored Procedures on a Multi-node/ Shared Cluster
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-23-2023 05:46 AM
Hi,
we are trying to move some of our code from a ‘legacy’ cluster to a ‘Multi-node/ Shared' cluster so that we can start using Unity Catalog. However, we have run into an issue with some of our code, which calls Stored Procedures, on the new cluster. I would appreciate any guidance the community can supply.
Our legacy configuration was a High Concurrency cluster (not configured with Table Access Control). On that Cluster we were using pyodbc to execute stored procedures to Read/ Write and Update tables in an Azure SQL database.
To do this we installed the unixodbc and pyodbc as part of the cluster startup init file (pretty much using the approach outlined in the answer in this thread https://stackoverflow.com/questions/54132249/how-to-install-pyodbc-in-databricks).
Once installed, we happily call a range of stored procedures on the Azure SQL database from the legacy cluster (as mentioned above the procs do all manner of reads, writes and updates).
Last week tried to move our code to a "Multi-node/Shared" cluster linked to Unity Catalog and we have run into an issue: namely we’ve been unable to find a way to execute our stored procedures on the new cluster.
Here is what we have tried and what we found:
Approach 1: Try using pyodbc and install the unix odbc drivers
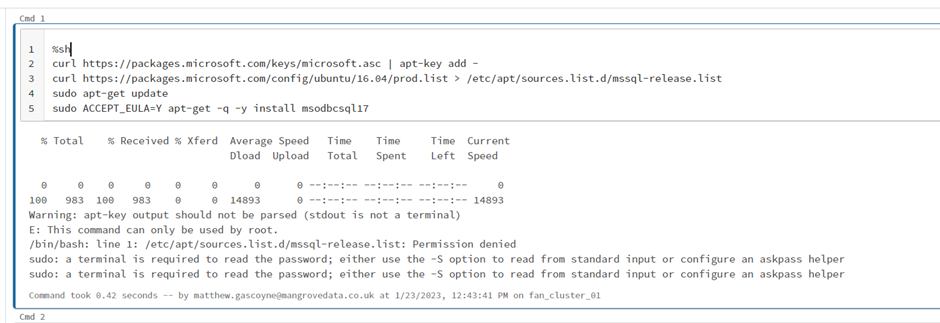
Whilst the pyodbc library can be imported into the notebook on the new Cluster, when we try and run pyodbc we get the below message which indicates that the required odbc drivers are not available.

When we manually tried to run the install of the odbc drivers we are informed we do not have permissions on the new cluster (fyi - trying to driver install via Global Inits also does not appear to have been successful).

Our working understanding of why this is the case is that the “Multi-node / Shared” clusters are a more locked down configuration and does not allow root level modifications (such as installing new drivers). Does that sound right?
Approach 2: Switch to using Jdbc to run the Stored Procedures
Using our legacy Cluster we adapted the way we execute stored procedures and took pyodbc out of the picture. Instead we executed the stored procedures using jdbc. (The below thread provides an example of how we tried to do this https://stackoverflow.com/questions/60354376/how-to-execute-a-stored-procedure-in-azure-databricks-p...
Whilst we got this approach working on the our legacy cluster, on the "Multi-node / Shared" cluster we got the below error informing we have a package whitelisting issue.
py4j.security.Py4JSecurityException: Method public static java.sql.Connection java.sql.DriverManager.getConnection(java.lang.String,java.lang.String,java.lang.String) throws java.sql.SQLException is not whitelisted on class class java.sql.DriverManager

Approach 3: Use Jdbc with direct Inserts
Using the Multi-node/ Shared cluster we have successfully used jdbc to both read and write to the Azure SQL table however from what we can see there is not way to run an UPDATE using jdbc so this is not an ideal solution but is our active work-around.
Before accepting our fate and moving away from executing stored procedures (something I know many would recommend anyway but will incur quite a bit of effort), I wanted to check whether the community had any ideas?
Thanks in advance
Labels:
- Labels:
-
Multi
-
Unity Catalog


7 REPLIES 7
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-23-2023 05:54 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-23-2023 06:01 AM
Thanks Hubert, that table is certainly consistent with what we have seen, i.e. we could use our legacy stored proc scripts on a Single User cluster but not with the Multi-node/ Shared (User Isolation) cluster. I am curious whether anyone found an alternative method of calling stored procs on a User Isolation cluster.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-23-2023 06:23 AM
take a look in Azure for "Automation Accounts" there you can add a webhook to call the procedure. Additionally, you can use Approach 3 Use Jdbc with direct Inserts.
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-19-2023 08:12 AM
We face the same issue. Our code depends heavily on stored procedures (best practice, no).
Unfortunately, when moving to shared clusters and DBR 13.3, this does not work anymore.
driver_manager = spark._sc._gateway.jvm.java.sql.DriverManager
connection = driver_manager.getConnection(_MetaDBJDBCconnectionUrl, _MetaDBUserName, _MetaDBPassword)
connection.prepareCall(sqlExecuteStatement).execute()
connection.close()now throws the error
An error occurred while calling z:java.sql.DriverManager.getConnection. Trace:
py4j.security.Py4JSecurityException: Method public static java.sql.Connection java.sql.DriverManager.getConnection(java.lang.String,java.lang.String,java.lang.String) throws java.sql.SQLException is not whitelisted on class class java.sql.DriverManageras listed above.
Going for approach 3 does not work in our case.
Any other suggestions?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-07-2024 01:58 AM
Hello, did you find a solution to this or a workaround ?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-07-2024 02:14 AM
Hi,
We switched to using the pymssql library.
Incomplete code sample to give you an idea:
import pymssql
# strParamList is comma separated list of @Param="some value"
sqlExecuteStoredProc = f"exec {strStoredProcName} {strParamList}"
_MetaDBConnection = pymssql.connect(_MetaDBServerName, _MetaDBUserName, _MetaDBPassword, _MetaDBDatabaseName)
cursor = _MetaDBConnection.cursor(as_dict=True)
cursor.execute(sqlExecuteStoredProc)
_MetaDBConnection.commit()
_MetaDBConnection.close()
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-26-2025 07:51 AM
@TjommeV-VlaioSwitching to Pymssql worked for your ?
interested to know in detail
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Valid init script for installing ODBC Driver 18 for SQL Server to a job cluster in Data Engineering
- Leveraging AI Assistant in Data Engineering Workflows - Share Your Use Cases & Best Practices in Data Engineering
- Can’t save results to target table – out-of-memory error in Data Engineering
- Assigning Dedicated (SINGLE_USER) ML Clusters to a Group in Databricks in Administration & Architecture
- How to execute SQL stored procedure in Azure Database for SQL Server using Azure Databricks Notebook in Data Engineering