- 2979 Views
- 1 replies
- 0 kudos
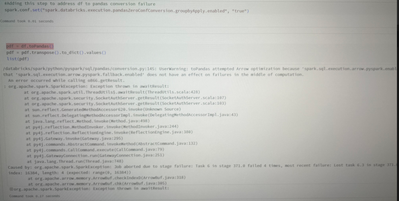
Dataframes to Pandas conversion step is failing with exception ""java.lang.IndexOutOfBoundsException: index: 16384, length: 4 (expected: range(0, 16384))"
Dataframes to Pandas conversion step is failing with exception ""java.lang.IndexOutOfBoundsException: index: 16384, length: 4 (expected: range(0, 16384))", PFB screenshot for more details
- 2979 Views
- 1 replies
- 0 kudos
Latest Reply
- 0 kudos
Hi @Vindhya D Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers you...
- 0 kudos