- 7672 Views
- 5 replies
- 5 kudos
Does FeatureStoreClient().score_batch support multidimentional predictions?
I have a pyfunc model that I can use to get predictions. It takes time series data with context information at each date, and produces a string of predictions. For example:The data is set up like below (temp/pressure/output are different than my inpu...
- 7672 Views
- 5 replies
- 5 kudos
- 5 kudos
I have the same question. I've decided to look for alternative Feature Stores as this makes it very difficult to use for time series forecasting.
- 5 kudos
- 5122 Views
- 3 replies
- 0 kudos
- 5122 Views
- 3 replies
- 0 kudos
- 0 kudos
You can take all the Databricks exams as many times as you want, but you have to pay a fee each time you take the exam.
- 0 kudos
- 2357 Views
- 2 replies
- 0 kudos
Tracking changes in data distribution by using pyspark
Hi All,I'm working on creating a data quality dashboard. I've created few rules like checking nulls in a column, checking for data type of the column , removing duplicates etc.We follow medallion architecture and are applying these data quality check...
- 2357 Views
- 2 replies
- 0 kudos
- 0 kudos
Hi @Sridhar Varanasi Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.T...
- 0 kudos
- 6365 Views
- 3 replies
- 0 kudos
Throwing IndexoutofBound Exception in Pyspark
Hello All,I am trying to read the data and trying to group the data in order to pass it to predict function via @F.pandas_udf method.#Loading Model pkl_model = pickle.load(open(filepath,'rb')) # build schema for output labels filter_schema=[] ...
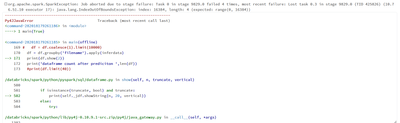
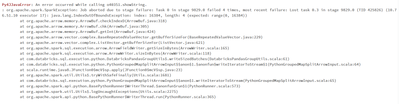
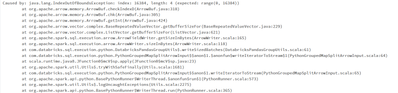
- 6365 Views
- 3 replies
- 0 kudos
- 0 kudos
@Santhanalakshmi Manoharan Was this issue resolved, Am also getting same error, any guidance would be of great help.Appreciate your help.
- 0 kudos
- 2931 Views
- 2 replies
- 0 kudos
TF SummaryWriter flush() don't send any buffered data to storage.
Hey guys, I'm training a TF model in databricks, and logging to tensorboard using SummaryWriter. At the end of each epoch SummaryWriter.flush() is called which should send any buffered data into storage. But i can't see the tensorboard files while th...
- 2931 Views
- 2 replies
- 0 kudos
- 0 kudos
Hi @orian hindi Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us so w...
- 0 kudos
- 7559 Views
- 1 replies
- 1 kudos
Resolved! Using databricks in multi-cloud, and querying data from the same instance.
I'm looking for a good product to use across two clouds at once for Data Engineering, Data modeling and governance. I currently have a GCP platform, but most of my data and future data goes through Azure, and currently is then transfered to GCS/BQ.Cu...
- 7559 Views
- 1 replies
- 1 kudos
- 1 kudos
@Karl Andrén :Databricks is a great option for data engineering, data modeling, and governance across multiple clouds. It supports integrations with multiple cloud providers, including Azure, AWS, and GCP, and provides a unified interface to access ...
- 1 kudos
- 1488 Views
- 0 replies
- 4 kudos
Hello Databricks Community! We are getting really excited about the upcoming event of the year Data & AI Summit 2023! The world’s largest data, a...
Hello Databricks Community! We are getting really excited about the upcoming event of the year Data & AI Summit 2023!The world’s largest data, analytics and AI conference returns live, to San Francisco and virtually. Four days (June 26–29, 2023) pack...
- 1488 Views
- 0 replies
- 4 kudos
- 9880 Views
- 3 replies
- 15 kudos
Resolved! Do One-Hot-Encoding (OHE) before or after split data to train and test dataframe
Hi,I wonder that I should do OHE before or after I split data to build up a ML model.Please give some advise.
- 9880 Views
- 3 replies
- 15 kudos
- 15 kudos
Hi @Nhat Hoang ,While not Databricks-specific, here's a good answer:"If you perform the encoding before the split, it will lead to data leakage (train-test contamination). In this sense, you will introduce new data (integers of Label Encoders) and u...
- 15 kudos
-
Access control
3 -
Access Data
2 -
AccessKeyVault
1 -
ADB
2 -
Airflow
1 -
Amazon
2 -
Apache
1 -
Apache spark
3 -
APILimit
1 -
Artifacts
1 -
Audit
1 -
Autoloader
6 -
Autologging
2 -
Automation
2 -
Automl
45 -
Aws databricks
1 -
AWSSagemaker
1 -
Azure
32 -
Azure active directory
1 -
Azure blob storage
2 -
Azure data lake
1 -
Azure Data Lake Storage
3 -
Azure data lake store
1 -
Azure databricks
32 -
Azure event hub
1 -
Azure key vault
1 -
Azure sql database
1 -
Azure Storage
2 -
Azure synapse
1 -
Azure Unity Catalog
1 -
Azure vm
1 -
AzureML
2 -
Bar
1 -
Beta
1 -
Better Way
1 -
BI Integrations
1 -
BI Tool
1 -
Billing and Cost Management
1 -
Blob
1 -
Blog
1 -
Blog Post
1 -
Broadcast variable
1 -
Business Intelligence
1 -
CatalogDDL
1 -
Centralized Model Registry
1 -
Certification
2 -
Certification Badge
1 -
Change
1 -
Change Logs
1 -
Check
2 -
Classification Model
1 -
Cloud Storage
1 -
Cluster
10 -
Cluster policy
1 -
Cluster Start
1 -
Cluster Termination
2 -
Clustering
1 -
ClusterMemory
1 -
CNN HOF
1 -
Column names
1 -
Community Edition
1 -
Community Edition Password
1 -
Community Members
1 -
Company Email
1 -
Condition
1 -
Config
1 -
Configure
3 -
Confluent Cloud
1 -
Container
2 -
ContainerServices
1 -
Control Plane
1 -
ControlPlane
1 -
Copy
1 -
Copy into
2 -
CosmosDB
1 -
Courses
2 -
Csv files
1 -
Dashboards
1 -
Data
8 -
Data Engineer Associate
1 -
Data Engineer Certification
1 -
Data Explorer
1 -
Data Ingestion
2 -
Data Ingestion & connectivity
11 -
Data Quality
1 -
Data Quality Checks
1 -
Data Science & Engineering
2 -
databricks
5 -
Databricks Academy
3 -
Databricks Account
1 -
Databricks AutoML
9 -
Databricks Cluster
3 -
Databricks Community
5 -
Databricks community edition
4 -
Databricks connect
1 -
Databricks dbfs
1 -
Databricks Feature Store
1 -
Databricks Job
1 -
Databricks Lakehouse
1 -
Databricks Mlflow
4 -
Databricks Model
2 -
Databricks notebook
10 -
Databricks ODBC
1 -
Databricks Platform
1 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Runtime
9 -
Databricks SQL
8 -
Databricks SQL Permission Problems
1 -
Databricks Terraform
1 -
Databricks Training
2 -
Databricks Unity Catalog
1 -
Databricks V2
1 -
Databricks version
1 -
Databricks Workflow
2 -
Databricks Workflows
1 -
Databricks workspace
2 -
Databricks-connect
1 -
DatabricksContainer
1 -
DatabricksML
6 -
Dataframe
3 -
DataSharing
1 -
Datatype
1 -
DataVersioning
1 -
Date Column
1 -
Dateadd
1 -
DB Notebook
1 -
DB Runtime
1 -
DBFS
5 -
DBFS Rest Api
1 -
Dbt
1 -
Dbu
1 -
DDL
1 -
DDP
1 -
Dear Community
1 -
DecisionTree
1 -
Deep learning
4 -
Default Location
1 -
Delete
1 -
Delt Lake
4 -
Delta lake table
1 -
Delta Live
1 -
Delta Live Tables
6 -
Delta log
1 -
Delta Sharing
3 -
Delta-lake
1 -
Deploy
1 -
DESC
1 -
Details
1 -
Dev
1 -
DevOps
1 -
Df
1 -
Different Notebook
1 -
Different Parameters
1 -
DimensionTables
1 -
Directory
3 -
Disable
1 -
Distribution
1 -
DLT
6 -
DLT Pipeline
3 -
Dolly
5 -
Dolly Demo
2 -
Download
2 -
EC2
1 -
Emr
2 -
Ensemble Models
1 -
Environment Variable
1 -
Epoch
1 -
Error handling
1 -
Error log
2 -
Eventhub
1 -
Example
1 -
Experiments
4 -
External Sources
1 -
Extract
1 -
Fact Tables
1 -
Failure
2 -
Feature Lookup
2 -
Feature Store
62 -
Feature Store API
2 -
Feature Store Table
1 -
Feature Table
6 -
Feature Tables
4 -
Features
2 -
FeatureStore
2 -
File Path
2 -
File Size
1 -
Fine Tune Spark Jobs
1 -
Forecasting
2 -
Forgot Password
2 -
Garbage Collection
1 -
Garbage Collection Optimization
1 -
Github
2 -
Github actions
2 -
Github Repo
2 -
Gitlab
1 -
GKE
1 -
Global Init Script
1 -
Global init scripts
4 -
Governance
1 -
Hi
1 -
Horovod
1 -
Html
1 -
Hyperopt
4 -
Hyperparameter Tuning
2 -
Iam
1 -
Image
3 -
Image Data
1 -
Inference Setup Error
1 -
INFORMATION
1 -
Input
1 -
Insert
1 -
Instance Profile
1 -
Int
2 -
Interactive cluster
1 -
Internal error
1 -
Invalid Type Code
1 -
IP
1 -
Ipython
1 -
Ipywidgets
1 -
JDBC Connections
1 -
Jira
1 -
Job
4 -
Job Parameters
1 -
Job Runs
1 -
Join
1 -
Jsonfile
1 -
Kafka consumer
1 -
Key Management
1 -
Kinesis
1 -
Lakehouse
1 -
Large Datasets
1 -
Latest Version
1 -
Learning
1 -
Limit
3 -
LLM
3 -
LLMs
3 -
Local computer
1 -
Local Machine
1 -
Log Model
2 -
Logging
1 -
Login
1 -
Logs
1 -
Long Time
2 -
Low Latency APIs
2 -
LTS ML
3 -
Machine
3 -
Machine Learning
24 -
Machine Learning Associate
1 -
Managed Table
1 -
Max Retries
1 -
Maximum Number
1 -
Medallion Architecture
1 -
Memory
3 -
Metadata
1 -
Metrics
3 -
Microsoft azure
1 -
ML Lifecycle
4 -
ML Model
4 -
ML Practioner
3 -
ML Runtime
1 -
MlFlow
75 -
MLflow API
5 -
MLflow Artifacts
2 -
MLflow Experiment
6 -
MLflow Experiments
3 -
Mlflow Model
10 -
Mlflow registry
3 -
Mlflow Run
1 -
Mlflow Server
5 -
MLFlow Tracking Server
3 -
MLModels
2 -
Model Deployment
4 -
Model Lifecycle
6 -
Model Loading
2 -
Model Monitoring
1 -
Model registry
5 -
Model Serving
29 -
Model Serving Cluster
2 -
Model Serving REST API
6 -
Model Training
2 -
Model Tuning
1 -
Models
8 -
Module
3 -
Modulenotfounderror
1 -
MongoDB
1 -
Mount Point
1 -
Mounts
1 -
Multi
1 -
Multiline
1 -
Multiple users
1 -
Nested
1 -
New Feature
1 -
New Features
1 -
New Workspace
1 -
Nlp
3 -
Note
1 -
Notebook
6 -
Notification
2 -
Object
3 -
Onboarding
1 -
Online Feature Store Table
1 -
OOM Error
1 -
Open Source MLflow
4 -
Optimization
2 -
Optimize Command
1 -
OSS
3 -
Overwatch
1 -
Overwrite
2 -
Packages
2 -
Pandas udf
4 -
Pandas_udf
1 -
Parallel
1 -
Parallel processing
1 -
Parallel Runs
1 -
Parallelism
1 -
Parameter
2 -
PARAMETER VALUE
2 -
Partner Academy
1 -
Pending State
2 -
Performance Tuning
1 -
Photon Engine
1 -
Pickle
1 -
Pickle Files
2 -
Pip
2 -
Points
1 -
Possible
1 -
Postgres
1 -
Pricing
2 -
Primary Key
1 -
Primary Key Constraint
1 -
Progress bar
2 -
Proven Practices
2 -
Public
2 -
Pymc3 Models
2 -
PyPI
1 -
Pyspark
6 -
Python
21 -
Python API
1 -
Python Code
1 -
Python Function
3 -
Python Libraries
1 -
Python Packages
1 -
Python Project
1 -
Pytorch
3 -
Reading-excel
2 -
Redis
2 -
Region
1 -
Remote RPC Client
1 -
RESTAPI
1 -
Result
1 -
Runtime update
1 -
Sagemaker
1 -
Salesforce
1 -
SAP
1 -
Scalability
1 -
Scalable Machine
2 -
Schema evolution
1 -
Script
1 -
Search
1 -
Security
2 -
Security Exception
1 -
Self Service Notebooks
1 -
Server
1 -
Serverless
1 -
Serving
1 -
Shap
2 -
Size
1 -
Sklearn
1 -
Slow
1 -
Small Scale Experimentation
1 -
Source Table
1 -
Spark config
1 -
Spark connector
1 -
Spark Error
1 -
Spark MLlib
2 -
Spark Pandas Api
1 -
Spark ui
1 -
Spark Version
2 -
Spark-submit
1 -
SparkML Models
2 -
Sparknlp
3 -
Spot
1 -
SQL
19 -
SQL Editor
1 -
SQL Queries
1 -
SQL Visualizations
1 -
Stage failure
2 -
Storage
3 -
Stream
2 -
Stream Data
1 -
Structtype
1 -
Structured streaming
2 -
Study Material
1 -
Summit23
2 -
Support
1 -
Support Team
1 -
Synapse
1 -
Synapse ML
1 -
Table
4 -
Table access control
1 -
Tableau
1 -
Task
1 -
Temporary View
1 -
Tensor flow
1 -
Test
1 -
Timeseries
1 -
Timestamps
1 -
TODAY
1 -
Training
6 -
Transaction Log
1 -
Trying
1 -
Tuning
2 -
UAT
1 -
Ui
1 -
Unexpected Error
1 -
Unity Catalog
12 -
Use Case
2 -
Use cases
1 -
Uuid
1 -
Validate ML Model
2 -
Values
1 -
Variable
1 -
Vector
1 -
Versioncontrol
1 -
Visualization
2 -
Web App Azure Databricks
1 -
Weekly Release Notes
2 -
Whl
1 -
Worker Nodes
1 -
Workflow
2 -
Workflow Jobs
1 -
Workspace
2 -
Write
1 -
Writing
1 -
Z-ordering
1 -
Zorder
1
- « Previous
- Next »