- 2007 Views
- 1 replies
- 0 kudos
Error ingesting files with databricks jobs
The source path that i want to ingest files with is:"gs://bucket-name/folder1/folder2/*/*.json"I have a file in this path that ends with ".json.gz" and the databricks job ingests this file even though it doesn't suppose to.How can i fix it?Thanks.
- 2007 Views
- 1 replies
- 0 kudos
- 9864 Views
- 0 replies
- 0 kudos
Deleted the s3 bucket assocated with metastore
I deleted the aws s3 bucket for the databricks metastore by mistake.How to fix this? can I re-create the s3 bucket? Or can I delete the metastore (I don't have much data in it), and re-generate one? Thank you!
- 9864 Views
- 0 replies
- 0 kudos
- 15245 Views
- 2 replies
- 1 kudos
Resolved! Not able to access Account console page
Hello All,I'm not be able to access the account console page. I'm a portal admin, my workspace is premium, and yet the Databricks portal stays in a loop, always returning to the Workspaces Overview page and not going to the accounts console page so t...
- 15245 Views
- 2 replies
- 1 kudos
- 1 kudos
Guys, the problem is that I was not signed in as a Global Administrator in Azure AD. After that, I reset all the Browser settings and I was able to do that. Here's the tip.
- 1 kudos
- 2260 Views
- 1 replies
- 1 kudos
Performance issue while calling Sagemaker Endpoint in pyspark udf
Hi,I have pyspark dataframe which calls pyspark udf which in turn calls sagemaker endpoint. But when dataframe has more rows, endpoint start failing. Also it takes longer to process.Please suggest how to call sagemaker endpoint from pyspark.Regards,S...
- 2260 Views
- 1 replies
- 1 kudos
- 2282 Views
- 0 replies
- 0 kudos
org.apache.spark.SparkException - FileReadException
Sometimes getting this kind of error "org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 12224.0 failed 4 times, most recent failure: Lost task 1.5 in stage 12224.0 (TID ) (12.xxx.x.xxx executor 1): com.datab...
- 2282 Views
- 0 replies
- 0 kudos
- 4042 Views
- 2 replies
- 0 kudos
how to edit or delete the post in this community
how to edit or delete the post in this community
- 4042 Views
- 2 replies
- 0 kudos
- 4900 Views
- 3 replies
- 1 kudos
Add Oracle Jar to Databricks cluster policy
I created a policy for users to use when they create their own Job clusters. When I'm editing the policy, I don't have the UI options for adding library (I can only see Definitions and Permissions tabs). I need to add via JSON the option to allows th...
- 4900 Views
- 3 replies
- 1 kudos
- 1 kudos
@adrianhernandez are you admin to workspace, if not you might be missing permissions, if you have policies enabled, admin can allow you.https://docs.databricks.com/en/administration-guide/clusters/policies.html#librariesif your workspace is Unity cat...
- 1 kudos
- 2453 Views
- 2 replies
- 1 kudos
Web terminal and clusters
Hi, I have come across this piece of documentation:Databricks does not support running Spark jobs from the web terminal. In addition, Databricks web terminal is not available in the following cluster types:Job clustersClusters launched with the DISAB...
- 2453 Views
- 2 replies
- 1 kudos
- 1 kudos
Hi @Retired_mod ,any update on my question? Thanks.
- 1 kudos
- 4869 Views
- 0 replies
- 0 kudos
Creating java UDF for Spark SQL
Hello, I have created a sample java UDF which masks few characters of a string. However I facing couple of issues when uploading and using it.First I could only import it, which for now is OK. But when do the following,create function udf_mask as 'ba...
- 4869 Views
- 0 replies
- 0 kudos
- 3154 Views
- 0 replies
- 2 kudos
dbutils.fs.ls MAX_LIST_SIZE_EXCEEDED
Hi!I'm experiencing different behaviours between two DBX Workspaces when trying to list file contents from an abfss: location.In workspace A running len(dbutils.fs.ls('abfss://~~@~~~~.dfs.core.windows.net/~~/')) results in "Out[1]: 1551", while runni...
- 3154 Views
- 0 replies
- 2 kudos
- 23062 Views
- 3 replies
- 4 kudos
Training @ Data & AI World Tour 2023
Join your peers at the Data + AI World Tour 2023! Explore the latest advancements, hear real-world case studies and discover best practices that deliver data and AI transformation. From the Databricks Lakehouse Platform to open source technologies in...

- 23062 Views
- 3 replies
- 4 kudos
- 4 kudos
Introducing Mini Flush: Your Ticket to Ultimate Casino Thrills!Are you ready to embark on an electrifying journey into the world of online gambling? If so, look no further than Vijaybet Online Casino! Our state-of-the-art platform is your gateway to ...
- 4 kudos
- 2961 Views
- 1 replies
- 1 kudos
Resolved! Problem creating external delta table on non-AWS s3 bucket
I am testing Databricks with non-AWS S3 object storage. I can access the non-AWS S3 bucket by setting these parameters:sc._jsc.hadoopConfiguration().set("fs.s3a.access.key", "XXXXXXXXXXXXXXXXXXXX")sc._jsc.hadoopConfiguration().set("fs.s3a.secret.key...


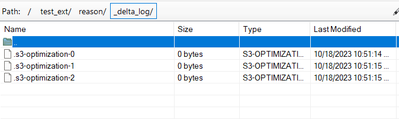
- 2961 Views
- 1 replies
- 1 kudos
- 1 kudos
Found the solution to disable it. Can close this question.
- 1 kudos
- 5802 Views
- 3 replies
- 1 kudos
getArgument works fine in interactive cluster 10.4 LTS, raises error in interactive cluster 10.4 LTS
Hello,I am trying to use the getArgument() function in a spark.sql query. It works fine if I run the notebook via an interactive cluster, but gives an error when executed via a job run in an instance Pool.query:OPTIMIZE <table>where date = replace(re...
- 5802 Views
- 3 replies
- 1 kudos
- 1 kudos
Hi @Retired_mod,Would you be able to respond to my last comment? I couldn't manage to get it working yet.Thank you in advance.
- 1 kudos
- 28801 Views
- 0 replies
- 3 kudos
Schema owned by Service Principal shows error in PBI
Background info:1. We have unity catalog enabled. 2. All of our jobs are run by Service Principal that has all necessary access it needs.Issue:One of the jobs checks existing schemas against the ones it is supposed to create in that given run and if ...

- 28801 Views
- 0 replies
- 3 kudos
- 4051 Views
- 1 replies
- 0 kudos
AWS Databricks VS AWS EMR
HiWhich services should I use for data lake implementation?any cost comparison between Databricks and aws emr.which one is best to choose
- 4051 Views
- 1 replies
- 0 kudos
- 0 kudos
@AH that depends on use case, if your implementation involves Data Lake, ML, Data engineering tasks better to go with databricks as it has got good UI and there good governance using unity catalog for your data lake and you have good consumer tool su...
- 0 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
AIBI
1 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Course
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
DAIS2026
1 -
Dashboards
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
5 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
2 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks Error Message
1 -
Databricks genAI associate
1 -
Databricks JDBC Driver
2 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Partner
1 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Genie
1 -
Getting started
3 -
Google Bigquery
1 -
Grafana
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
ISVPartnership
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
link for labs
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Market Place
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
mosic ai search
1 -
Networking
2 -
Notebook
1 -
Onboarding
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
plugins
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 46 | |
| 40 |