- 1468 Views
- 1 replies
- 0 kudos
Exam suspended
Hello Databricks Team,I had a terrible experience during certification exam and I have also raised a ticket to the Databricks team but haven’t got any response to the mail till now. I appeared for the Databricks certified Associate Developer for Apa...
- 1468 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @Cert-Team Could you please look into this issue and assist me in rescheduling my exam since it’s very important for me to provide my certification to my employer at the earliest.Thanks and RegardsHaneen Heeba
- 0 kudos
- 4051 Views
- 1 replies
- 1 kudos
Resolved! Remove duplicate records using pyspark
Hi,I am trying to remove duplicate records from pyspark dataframe and keep the latest one. But somehow df.dropDuplicates["id"] keeps the first one instead of latest. One of the option is to use pandas drop_duplicates, Is there any solution in pyspark...
- 4051 Views
- 1 replies
- 1 kudos
- 1 kudos
Hi @sanjay ,You can write window function that will rank your rows and then filter rows based on that rank.Take a look on below stackoverflow thread: https://stackoverflow.com/questions/63343958/how-to-drop-duplicates-but-keep-first-in-pyspark-datafr...
- 1 kudos
- 2058 Views
- 1 replies
- 0 kudos
best practices for implementing early arriving fact handling
Hi All,Can you please share us the best practices for implementing early arriving fact handling in databricks for streaming data processed in near real time using structured streaming.There are many ways to handle this use case in batch/mini batch. ...

- 2058 Views
- 1 replies
- 0 kudos
- 0 kudos
Greetings Team, I would like to inquire if any of you have suggestions regarding the query.
- 0 kudos
- 1415 Views
- 0 replies
- 0 kudos
Any women in data+ai interested in gathering to form some a casual networking group based in Sydney?
Hi all,Inspired by the Women in Data+AI Breakfast at the Databricks World Tour in Sydney, I'm considering the potential for a new womens' networking community based in Sydney. This group would cater to women currently working in or interested in purs...
- 1415 Views
- 0 replies
- 0 kudos
- 10536 Views
- 13 replies
- 4 kudos
Can't activate users
A while back apparently a user became inactive on our Databricks platform from unknown reason.So far everything we tried haven't worked:Delete and manually re-create the userDelete and let SSO to create the user on loginUse Databricks CLI - shows no ...
- 10536 Views
- 13 replies
- 4 kudos
- 4 kudos
I had the same issue on my admin account seamlessly becoming inactive at random.The problem occurred after helping our platform team testing out a new setup of another databricks workspace.I was testing the setup logging in as a standard user and an ...
- 4 kudos
- 3100 Views
- 0 replies
- 1 kudos
Installation of cluster requirements.txt does not appear to run as google service account
I am running on 15.4 LTS Beta, which supports cluster-level requirements.txt files. The particular requirements.txt I have uploaded to my workspace specifies an extra index URL using a first line that looks like--extra-index-url https://us-central1-p...
- 3100 Views
- 0 replies
- 1 kudos
- 1434 Views
- 0 replies
- 0 kudos
Apply Changes Error in DLT Pipeline
Hi Team, Am Trying to use Apply changes from Bronze to Silver using the below. @dlt.table( name="Silver_Orders", comment="This table - hive_metastore.silver.Orders reads data from the Bronze layer and writes it t...
- 1434 Views
- 0 replies
- 0 kudos
- 5350 Views
- 5 replies
- 1 kudos
Resolved! Unable to connect to SQL Warehouse from RStudio using U2M authentication
Hi Community,Has anyone encountered the error below, and If yes, how did you solve it? My workspace is setup normally in UC. My workspace also has private endpoint setup. I am authentication over the browser when I run my R code, then right after the...
- 5350 Views
- 5 replies
- 1 kudos
- 1 kudos
Thanks everyone for the replies. It turned out that this is a known bug and they are working on a fix
- 1 kudos
- 5999 Views
- 3 replies
- 1 kudos
Databricks Asset Bundles - terraform.tfstate not matching when using databricks bundle deploy
Hello I have notice something strange with the asset bundle deployments via the CLI toolI am trying to run databricks bundle deploy and i'm getting and error saying the job ID doesn't exist or I don't have access to it. Error: cannot read job: User h...
- 5999 Views
- 3 replies
- 1 kudos
- 1 kudos
hello,I experienced the same problem today. However i was able to fix it by deleting the tf statefile containing the deleted job. (Located in the .bundle folder in my workspace under the user/ service principal who deployed the bundle. )
- 1 kudos
- 595 Views
- 0 replies
- 0 kudos
Discover the Essence of Elegance: Jawaad Perfume by Lattafa Asad
Unveil a new level of sophistication with Jawaad Perfume by Lattafa Asad. This exquisite fragrance captures the essence of elegance through its meticulously crafted notes, blending timeless aromas into a harmonious symphony.
- 595 Views
- 0 replies
- 0 kudos
- 1340 Views
- 0 replies
- 0 kudos
Venicold G@l: cijena i učinkovitost liječenja proširenih vena u Croatia
Venicold G@L pomaže brzom zacjeljivanju krvnih žila nogu. Ovaj neinvazivni, brzodjelujući lijek razbija krvne ugruške koji smanjuju krvarenje, uzrokuju otežan protok krvi, tanje stijenke krvnih žila, povećanu viskoznost krvi i eventualno začepljenje ...
- 1340 Views
- 0 replies
- 0 kudos
- 641 Views
- 0 replies
- 0 kudos
DataBricks Certification Exam Got Suspended.
Hello , I was taking the Databricks Certified Data Engineer Associate exam when a pop-up appeared, warning me not to look away from the screen. However, I was focused solely on the screen and did not violate any exam rules.Afterwards , the proctor as...
- 641 Views
- 0 replies
- 0 kudos
- 818 Views
- 0 replies
- 0 kudos
Venicold G@l | Un prodotto che cura le vene varicose - Recensione di Italy
L'ultima generazione di G@L topico biologico Venicold G@L allevia la pesantezza delle gambe, le gambe doloranti e le vene gonfie. Per la guarigione delle vene varicose, penetra in profondità negli strati sottocutanei della pelle. Elimina e previene l...
- 818 Views
- 0 replies
- 0 kudos
- 796 Views
- 0 replies
- 0 kudos
Diabetic | Soutenez votre diabète avec des gelule abordables au Sénégal (évaluations positives)
Les médicaments contre le diabète préviennent les types 1 et 2. Sa gelule révolutionnaire augmente la sensibilité à l'insuline et normalise la glycémie sans utiliser de médicaments nocifs ou coûteux. Vous pouvez obtenir la solution à votre problème ...
- 796 Views
- 0 replies
- 0 kudos
- 780 Views
- 0 replies
- 0 kudos
Few Tables not getting creating in Overwatch installation in Azure Databricks
We have installed Overwatch in Azure Databricks environment.As mentioned in documentation, we did create storage account for cluster logs and mounted it in databricks. Similarly, enabled system tables for audit logs and created delta table for stori...
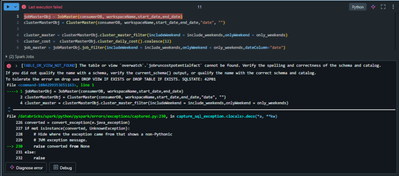
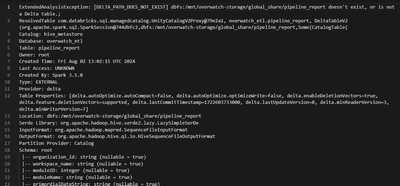
- 780 Views
- 0 replies
- 0 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
4 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
1 -
Databricks Apps
1 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks genAI associate
1 -
Databricks JDBC Driver
1 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
Declartive Pipelines
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Getting started
3 -
Google Bigquery
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeBase
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
mosic ai search
1 -
Networking
2 -
Notebook
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Unity Cataloge
1 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 45 | |
| 40 |