- 2321 Views
- 3 replies
- 1 kudos
how to implement delta load when table only has primary columns
I have a table where there are two columns and both are primary key, I want to do delta load when taking data from source to target. Any idea how to implement this?
- 2321 Views
- 3 replies
- 1 kudos
- 1 kudos
But that shouldn't be a problem. In merge condition you check both keys as in example above. If combination of two keysb already exists in the table then do nothing. If there is new combination of key1 and key2 just insert it into target table.It's t...
- 1 kudos
- 3912 Views
- 3 replies
- 0 kudos
how can I store my cell output as a text file in my local drive?
I want to store the output of my cell as a text file in my local hard drive.I'm getting the json output and I need that json in my local drive as a text file.
- 3912 Views
- 3 replies
- 0 kudos
- 0 kudos
Hi @InquisitiveGeek ,You can do this following below approach: https://learn.microsoft.com/en-us/azure/databricks/notebooks/notebook-outputs#download-results
- 0 kudos
- 3173 Views
- 2 replies
- 1 kudos
Can I move a single file larger than 100GB using dbtuils fs?
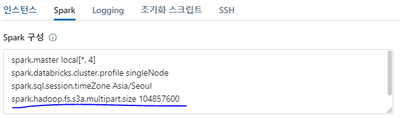
Hello. I have a file over 100GB. Sometimes this is on the cluster's local path, and sometimes it's on the volume.And I want to send this to another path on the volume, or to the s3 bucket. dbutils.fs.cp('file:///tmp/test.txt', '/Volumes/catalog/schem...
- 3173 Views
- 2 replies
- 1 kudos
- 1 kudos
Hi @himanmon ,This is caused because of S3 limit on segment count. The part files can be numbered only from 1 to 10000After Setting spark.hadoop.fs.s3a.multipart.size to 104857600. , did you RESTART the cluster? Because it'll only work when the clust...
- 1 kudos
- 4209 Views
- 1 replies
- 0 kudos
Resolved! error creating token when creating databricks_mws_workspace resource on GCP
resource "databricks_mws_workspaces" "this" { depends_on = [ databricks_mws_networks.this ] provider = databricks.account account_id = var.databricks_account_id workspace_name = "${local.prefix}-dbx-ws" location = var.google_region clou...
- 4209 Views
- 1 replies
- 0 kudos
- 0 kudos
my issue was caused be credentials in `~/.databrickscfg` (generated by databricks cli) taking precedence over the creds set by `gcloud auth application-default login`. google's application default creds should be used when using the databricks google...
- 0 kudos
- 5788 Views
- 2 replies
- 1 kudos
Resolved! Error - Data Masking
Hi,I was testing masking functionality of databricks and got the below error:java.util.concurrent.ExecutionException: com.databricks.sql.managedcatalog.acl.UnauthorizedAccessException:PERMISSION_DENIED: Query on table dev_retransform.uc_lineage.test_...

- 5788 Views
- 2 replies
- 1 kudos
- 1 kudos
Hi @FaizH , Are you using single user compute by any chance? Because of you do there is following limitation:Single-user compute limitationDo not add row filters or column masks to any table that you are accessing from a single-user cluster. During t...
- 1 kudos
- 4493 Views
- 3 replies
- 1 kudos
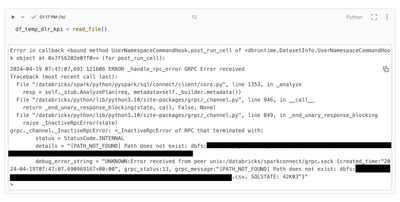
Resolved! Spark read CSV does not throw Exception if the file path is not available in Databricks 14.3
We were using this method and this was working as expected in Databricks 13.3. def read_file(): try: df_temp_dlr_kpi = spark.read.load(raw_path,format="csv", schema=kpi_schema) return df_temp_dlr_kpi except Exce...
- 4493 Views
- 3 replies
- 1 kudos
- 1 kudos
Hi, has this been resolved? I am still seeing this issue with Runtime 14.3 LTSThanks in advance.
- 1 kudos
- 2473 Views
- 1 replies
- 0 kudos
Connection with virtual machine
I have to upload files from Azure container to Virtual machine using Databricks. I have mounted my files to Databricks.Please help me do it. If any idea about this.
- 2473 Views
- 1 replies
- 0 kudos
- 0 kudos
I am not sure if you need to further curate the data before you upload it to Virtual machine, if you not you can just mount storage on VMCreate an SMB Azure file share and connect it to a Windows VM | Microsoft LearnAzure Storage - Create File Storag...
- 0 kudos
- 6343 Views
- 2 replies
- 1 kudos
Resolved! Access to "Admin Console" and "System Tables"
I am the contributor and owner of my databricks workspace. After a recent spike of expense, I want to check the billing details of my Azure databricks usage. (i.e per cluster, per VM, etc). Databricks provides these information thorough "Admin Conso...
- 6343 Views
- 2 replies
- 1 kudos
- 1 kudos
Hi @johnp , Thank you for reaching out to our community! We're here to help you. To ensure we provide you with the best support, could you please take a moment to review the response and choose the one that best answers your question? Your feedback...
- 1 kudos
- 1724 Views
- 1 replies
- 0 kudos
Liquid clustering with incremental ingestion
We ingest data incrementally from a database into delta tables using a column updatedUtc. This column is a datetime and is updated when the row in the database table changes. What about using this non-mutable column in "cluster by"? Would it require ...
- 1724 Views
- 1 replies
- 0 kudos
- 0 kudos
It recommended to run optimize query in scheduled manner https://docs.databricks.com/en/delta/clustering.html#how-to-trigger-clustering
- 0 kudos
- 815 Views
- 0 replies
- 1 kudos
- 815 Views
- 0 replies
- 1 kudos
- 855 Views
- 0 replies
- 0 kudos
Databricks feature
would like to know if databricks supports write back feature via altreyx to databricks.
- 855 Views
- 0 replies
- 0 kudos
- 2058 Views
- 1 replies
- 0 kudos
Setting up a proxy for python notebook
Hi all,I am running a python notebook with a web scraper. I want to setup a proxy server that I can use to avoid any IP bans when scraping. Can someone recommend a way to setup a proxy server that can be used from HTTP requests send from a Databricks...
- 2058 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi Kaniz,Thanks for the reply. I know how to include HTTP proxies in my python code and redirect the requests. However, I wondered if Databricks has any functionality to setup the proxies?Thank you
- 0 kudos
- 1568 Views
- 1 replies
- 0 kudos
Unity Catalog cannot display(), but can show() table
Hello all,I'm facing the following issue in a newly setup Azure Databricks - Unity Catalog environment:Failed to store the result. Try rerunning the command.Failed to upload command result to DBFS. Error message: PUT request to create file error Http...

- 1568 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @CharlesDLW , You have similar use case to the one below. Follow my reply in that thread: https://community.databricks.com/t5/community-discussions/file-found-with-fs-ls-but-not-with-spark-read/m-p/78618/highlight/true#M5972
- 0 kudos
- 4469 Views
- 2 replies
- 2 kudos
Resolved! jdbc errors when parameter is a boolean
I'm trying to query a table from Java code. The query works when I use a databricks notebook / query editor directly in Databricks. However, when using Jdbc with Spring, I get following stacktrace. org.springframework.jdbc.UncategorizedSQLException:...
- 4469 Views
- 2 replies
- 2 kudos
- 2 kudos
As I see it, there's two things:jdbcTemplate converts boolean to bit. This is according to JDBC specs (this is a "spring-jdbc" thing and according to documentation; the jdbcTemplate.queryForList makes the best possible guess of the desired type).Data...
- 2 kudos
- 1937 Views
- 1 replies
- 0 kudos
Databricks/Terraform - Error while creating workspace
Hi - I have below code to create the credentials, storage and workspace through terraform script but only credentials and storage is created but failed to create the workspace with error. Can someone please guide/suggest what's wrong with the code/l...
- 1937 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @Shrinivas , Could you share with us how you configured datbricks provider?
- 0 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
AIBI
1 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
DAIS2026
1 -
Dashboards
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
5 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
2 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks Error Message
1 -
Databricks genAI associate
1 -
Databricks JDBC Driver
2 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Partner
1 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Genie
1 -
Getting started
3 -
Google Bigquery
1 -
Grafana
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Market Place
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
Networking
2 -
Notebook
1 -
Onboarding
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
plugins
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 46 | |
| 40 |