- 10452 Views
- 2 replies
- 1 kudos
Maintaining Order Consistency: Table Creation in Databricks SQL vs. DLT Pipeline
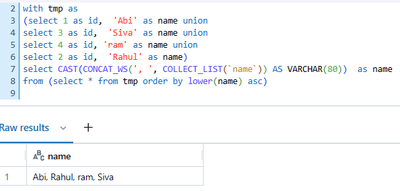
I have a CTE table with the below names as values. My objective is to create another table by concatenating all the rows from the CTE table in ascending order, resulting in the final output sequence: "Abi, Rahul, ram, Siva". When executing the query ...
- 10452 Views
- 2 replies
- 1 kudos
- 1 kudos
Hi @Archana_Mathan, did you solve this problem by any chance? I am having a similar problem maintaining the order of the dlt.Thank you,
- 1 kudos
- 1410 Views
- 0 replies
- 1 kudos
register for Databricks Community Edition
I've been trying to register for Databricks Community Edition for 3 days, to study the platform, but I'm experiencing an error when registering ("An error has occurred. Please try again later."). Could anyone help me, how do I register for the commun...
- 1410 Views
- 0 replies
- 1 kudos
- 3807 Views
- 1 replies
- 1 kudos
Resolved! Pandas .to_excel not saving to workspace
Hi!I was always able to export pandas datasets to my workspace on databricks, just like in a local machine using df.to_excel('filename', index=False).but since i got some permissions updates to some new catalogs, when i try to export a dataset using ...
- 3807 Views
- 1 replies
- 1 kudos
- 1 kudos
Just to update the situation, and to help anyone with the same problem in the future:What hapened was thas my cluster was updated to use Unity Catalogs, and with that i had to specify the full path to my workspace.df_pandas.to_excel('/Workspace/Users...
- 1 kudos
- 2283 Views
- 1 replies
- 1 kudos
Training/Fine-Tunning Foundation model
When I was tring ti run the dbdemos for llm-rag-fine-tuning I'm stuck on one of the first lines of code. When trying to execute the function: databricks.model.foundation_model.create(...) with the Mistral_7B_instruct_v2.0 it is failing with the follo...
- 2283 Views
- 1 replies
- 1 kudos
- 1 kudos
Currently using my account and the command dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiUrl().get().apiToken().get() to get my current databricks token to access this function. And my user just doesn't have admin permissions ...
- 1 kudos
- 1953 Views
- 1 replies
- 0 kudos
SAP Data in Databricks
Any one using SAP data to brining in to Databricks, do you directly hit SAP ODP or use any third party tool to get the data to datalake . Thanks,
- 1953 Views
- 1 replies
- 0 kudos
- 0 kudos
With the recent news form SAP, looks like SAP DataSphere will be the only way forward for, SAP
- 0 kudos
- 1579 Views
- 1 replies
- 0 kudos
Query for user persona for DB products
What is the typical user persona for DB products?
- 1579 Views
- 1 replies
- 0 kudos
- 0 kudos
Databricks supports many personas, the primary ones are Data Engineer, Data Scientisits, Data Analysts. but also, secondary ones are Analytics Engineers, Machine Learning Engineers, Data Stewareds, Data Administrators and Data Architect.
- 0 kudos
- 2474 Views
- 1 replies
- 2 kudos
Resolved! Is there any way to get notified for any new private preview and public preview features
As a databricks customer Is there any way to subscribe to get notified to email for any private preview and public preview features?
- 2474 Views
- 1 replies
- 2 kudos
- 2 kudos
Subscribe to the Databricks Newsletter and join the Quarterly Product Roadmap Webinars where they announce all the new private previews.
- 2 kudos
- 1629 Views
- 1 replies
- 0 kudos
Error in DLT Streaming table
HelloI am trying to create DLT streaming table in Azure Data bricks but getting following error. I checked online article regarding this error but none of the article shown complete resolution.[STREAM_FAILED] Query [id = 9989a41e-741d-48d7-9a87-fc143...
- 1629 Views
- 1 replies
- 0 kudos
- 0 kudos
HI @Retired_modCan you pls share the library or package name which contain "com.databricks.cdc.spark.DebeziumJDBCMicroBatchProvider" class. I tried to add databricks-cdc and Debezium library using maven but unable to install them because they are not...
- 0 kudos
- 2705 Views
- 0 replies
- 0 kudos
File Not Found Error while reading pickle file
Hello, thereI have a pickle file uploaded in a mounted location in databricks ( /dbfs/mnt/blob/test.pkl). I am trying to read this pickle file using the below python snippetwith open(path + "test.pkl", "rb") as f: bands = pickle.load(f)But it t...
- 2705 Views
- 0 replies
- 0 kudos
- 12174 Views
- 2 replies
- 0 kudos
Resolved! Using private package, getting ERROR: No matching distribution found for myprivatepackage
My project's setup.py filefrom setuptools import find_packages, setup PACKAGE_REQUIREMENTS = ["pyyaml","confluent-kafka", "fastavro", "python-dotenv","boto3", "pyxlsb", "aiohttp", "myprivatepackage"] LOCAL_REQUIREMENTS = ["delta-spark", "scikit-lea...
- 12174 Views
- 2 replies
- 0 kudos
- 0 kudos
Hi, Does this look like a dependency error? All the dependencies are packed in the whl? Also, could you please confirm if all the limitations are satified? Refer: https://docs.databricks.com/en/compute/access-mode-limitations.html
- 0 kudos
- 7789 Views
- 2 replies
- 0 kudos
Resolved! Is DBFS going to be deprecated?
Is DBFS going to be deprecated? As I am using /dbfs/FileStore/tables/ location where a jar file is stored, and I am copying this jar file to /databricks/jars locations.My concerns is as DBFS root and mounts are deprecated, is that mean in coming days...
- 7789 Views
- 2 replies
- 0 kudos
- 0 kudos
Hi Raphael,I am trying below init script to achieve this task, PFAAnd getting error as below,Cluster scoped init script abfss://container@storage.dfs.core.windows.net/init_script.sh failed: Failure to initialize configuration for storage account stor...
- 0 kudos
- 4726 Views
- 1 replies
- 2 kudos
How to update python's runtime on AWS lambda function
I heard that version 3.8 of Python on AWS Lambda will be EOL within the year. I would like to update this runtime, but where can I find the CloundFormation stack template.
- 4726 Views
- 1 replies
- 2 kudos
- 2 kudos
Thanks. I went to AWS Cloudformation stack and edited the template from python 3.8 to 3.12 and updated. I did this for both the workspace stack and the s3 ingestion stack. Will it break anything? Do I need to make any changes in the python code in th...
- 2 kudos
- 1397 Views
- 0 replies
- 0 kudos
Init_script in workspace
How can use init script stored in workspace which copies jar from storage account and put it inside /databricks/jars location. As said in init_script migration document, where your init scripts are “self-contained,” i.e., DO NOT reference other files...
- 1397 Views
- 0 replies
- 0 kudos
- 1563 Views
- 0 replies
- 0 kudos
com.databricks.backend.common.rpc.SparkDriverExceptions$SQLExecutionException: java.io.IOException:
I have been getting this error for the past few days while trying to create a table using parquet or csv options. The error is :IOException: s3a://AKIAJBRYNXGHORDHZB4A:a0BzE1bSegfydr3%2FGE3LSPM6uIV5A4hOUfpH8aFF@databricks-corp-training/common/online_...
- 1563 Views
- 0 replies
- 0 kudos
- 1589 Views
- 1 replies
- 2 kudos
Havent receive databricks associate certification
HiI passed my Databricks data engineer associate exam on 28 jun 2024. I haven't recieved my Certification even after 62 hours.Is any body facing the same issue?Tried to contacted databricks bt no response yet.Kindly help
- 1589 Views
- 1 replies
- 2 kudos
- 2 kudos
Same for me as well, I took exam on 29th Jun and still didn't receive the Certificate.
- 2 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
DAIS2026
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
4 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
2 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks genAI associate
1 -
Databricks JDBC Driver
1 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Partner
1 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Getting started
3 -
Google Bigquery
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Market Place
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
Networking
2 -
Notebook
1 -
Onboarding
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 45 | |
| 40 |