- 2391 Views
- 1 replies
- 2 kudos
Resolved! DAIS24 Attendee Badge - Oops
I wasn't at DAIS24, but I received one of these emails and it appears to have come from Databricks. I think I was given the badge in error. Can we have it removed?Just Wondering,Shawn

- 2391 Views
- 1 replies
- 2 kudos
- 2 kudos
Hi @Shawn_Eary Thank you for bringing this to our attention. We were conducting a test on badges, and some of our community members may have received this email by accident. We have revoked the changes now, please ignore the message.
- 2 kudos
- 3807 Views
- 1 replies
- 0 kudos
Tableau Prep Save Output to Databricks
Has anyone run into use cases where your data scientist/data engineer end users build Tableau Prep Flows and steps in Tableau Prep Flow require saving output back into Databricks? There appears to be no native support for this in Tableau Prep if the ...
- 3807 Views
- 1 replies
- 0 kudos
- 0 kudos
These are awesome suggestions. To expand on our setup, we also have Informatica Cloud - IICS (CMI, CDI, etc.) connected to the entire setup generally used for bringing data from a source (PaaS, SaaS, On-prem SQL, Flat Files or streaming devices) to D...
- 0 kudos
- 5211 Views
- 4 replies
- 1 kudos
Resolved! Getting error while running the MLOPS demo
Hello,I am trying to run this demo in databricks community edition but i am facing error.MLOPS DEMO - https://www.databricks.com/resources/demos/tutorials/data-science-and-ai/mlops-end-to-end-pipeline?itm_data=demo_centerSomeone else also faced the s...
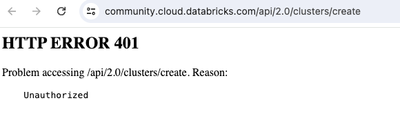
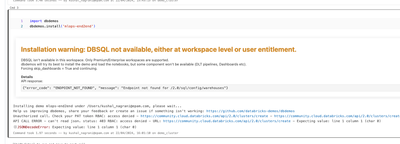
- 5211 Views
- 4 replies
- 1 kudos
- 1 kudos
Hey @Kushal_Nagrani , thank you for sharing this. I am facing the same issue. Could you please help me where can I find these settings? I am new, just created a community workspace and I thought given I am the admin I will have all these by default -...
- 1 kudos
- 1444 Views
- 0 replies
- 0 kudos
Training link deprecated: How to ingest data for Databricks SQL
I am currently doing a course in Databricks academy: How to ingest data for Databricks SQL.To create a table in the external location I am provided with the link that is not working anymore. Below is the link:wasbs://courseware@dbacademy.blob.core.wi...
- 1444 Views
- 0 replies
- 0 kudos
- 2156 Views
- 1 replies
- 0 kudos
Materialized Views Still In Public Preview?
The title is self-explanatory, but I'm curious if anyone has any inclination as to when Materialized Views will enter General Availability? I'm surprised it's not already in GA considering (A) it's been a year or more since Databricks originally anno...

- 2156 Views
- 1 replies
- 0 kudos
- 0 kudos
Yes, if the documentation states it, it's still in preview.
- 0 kudos
- 8929 Views
- 2 replies
- 0 kudos
Seeking Tips: Ways to Master Databricks on Azure?
Hello everyone. I'm currently learning Databricks on Azure through a Udemy course. Recently, I was surprised by a charge of $86 from Azure, which has made me cautious about continuing in this manner. Is there a more cost-effective approach to learn D...
- 8929 Views
- 2 replies
- 0 kudos
- 0 kudos
Thank you so much for the information.
- 0 kudos
- 3741 Views
- 1 replies
- 0 kudos
databricks asset bundles on azure devops
@herewe are able to work on DAB locally or Github actions, but looks from azure devops end lot of missing pieces in terms of pipeline and examples. can any one point me out github repo that is good to test azure devops pipeline for DAB.
- 3741 Views
- 1 replies
- 0 kudos
- 1705 Views
- 1 replies
- 0 kudos
Assigning a group as USER to service principal
How can we assigning a group as USER to service principal using databricks-sdk, this is not supported?
- 1705 Views
- 1 replies
- 0 kudos
- 0 kudos
I found this API, https://docs.databricks.com/api/account/accountaccesscontrol/updaterulesetbut its PUT and GET method both requires a parameter "etag", how can someone know this "etag"?
- 0 kudos
- 3397 Views
- 3 replies
- 2 kudos
DLT Compute: "Ephemeral" Job Compute vs. All-purpose compute
Hi there, I would like to understand for DLT jobs if there is any way to get DLT jobs running in an *existing* (and currently running) All-purpose compute rather than spinning up an "ephemeral" (not yet initialized) Job Compute?

- 3397 Views
- 3 replies
- 2 kudos
- 2 kudos
Hi @ChristianRRL , you cannot run a DLT pipeline in an All-purpose compute cluster. DLT Clusters are managed resources. Here are some details on how to configure a DLT cluster: https://docs.databricks.com/en/delta-live-tables/settings.html#configure-...
- 2 kudos
- 8098 Views
- 3 replies
- 0 kudos
List granted access for a group or a user
Is there any way where I can see what access a group or a user have been given to objects (Tables, views, catalogs etc.)?I noticed that we have the following information_schema tables:catalog_privilegesroutine_privilegestable_privilegesschema_privile...
- 8098 Views
- 3 replies
- 0 kudos
- 0 kudos
Hi @Henrik To grant a user the privilege to query system tables, a metastore admin or another privileged user must grant USE and SELECT permissions on the system schemas. GRANT USAGE ON CATALOG system TO <user_name>; GRANT USAGE ON SCHEMA informa...
- 0 kudos
- 21063 Views
- 3 replies
- 3 kudos
org.apache.spark.SparkException: Job aborted due to stage failure:
HiI have around 20 million records in my DF, and want to save it in HORIZINTAL SQL DB.This is error:org.apache.spark.SparkException: Job aborted due to stage failure: A shuffle map stage with indeterminate output was failed and retried. However, Spar...
- 21063 Views
- 3 replies
- 3 kudos
- 3 kudos
If there are any failures which may lead to a stage retry, but retrying the stage translates into potentially having an inconsistent result (indeterminacy) then this exception is raised. The exception is raised in newer version where the validation i...
- 3 kudos
- 2825 Views
- 0 replies
- 0 kudos
Databricks + confluent schema registry - Schema not found error
I am running a Kafka producer code on Databricks 12.2. I am testing AVRO serialization of message with help of confluent schema registry. I configured 'to_avro' function to read the schema from schema registry, but I am getting the below error> org.a...
- 2825 Views
- 0 replies
- 0 kudos
- 1700 Views
- 0 replies
- 0 kudos
Identifying the Dependency Automatically on the SQL Statements
Hi All,We have a SQL script file with lots of create, insert, and SQL statements. We need to figure out how to identify the dependencies between the statements dynamically(by using either spark/sql or using any program).For example - First, we need t...
- 1700 Views
- 0 replies
- 0 kudos
- 2315 Views
- 1 replies
- 0 kudos
Materialized view in DLT pipeline
When setting up DLT pipeline, there are 3 types of product edition, Core, Pro and Advanced. When I compare DLT Classic Core and DLT Classic Pro, the difference is that DLT Classic Pro can handle CDC. Does it means if I'm using DLT Classic Core, I hav...
- 2315 Views
- 1 replies
- 0 kudos
- 0 kudos
Also, If I'm using DLT Classic Core for DLT pipeline, the materialized view will be doing a full refresh or just update on the rows that have changes?
- 0 kudos
- 1856 Views
- 0 replies
- 0 kudos
Unzip multiple zip files in databricks
I have a zip file which in turn has multiple zip files inside it. I tried to write a code in databricks notebook to unzip all these files at once, but I ran into an error. So I started to unzip these one by one, but the code which worked in unzipping...
- 1856 Views
- 0 replies
- 0 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
AIBI
1 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
DAIS2026
1 -
Dashboards
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
5 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
2 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks Error Message
1 -
Databricks genAI associate
1 -
Databricks JDBC Driver
2 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Partner
1 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Genie
1 -
Getting started
3 -
Google Bigquery
1 -
Grafana
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Market Place
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
Networking
2 -
Notebook
1 -
Onboarding
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
plugins
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 46 | |
| 40 |