- 1766 Views
- 1 replies
- 2 kudos
Run mlflow project from a Job.
Hey Guys, I'm trying to make automated process to run ML training sessions using mlflow and databricks jobs.While developing the model on my local machine using IDE, When finished I have a template notebook that get as parameters the mlflow project p...

- 1766 Views
- 1 replies
- 2 kudos
- 2 kudos
Hi @orian hindi , We haven’t heard from you since the last response, and I was checking back to see if you have a resolution yet. If you have any solution, please share it with the community as it can be helpful to others. Otherwise, we will respon...
- 2 kudos
- 734 Views
- 0 replies
- 0 kudos
Prophet/PyStan compiling error in Runtime 10.4 LTS ML
We're upgrading our ML jobs from using Runtime 9.1 LTS ML to Runtime 10.4 LTS ML in Databricks. One of the libraries our jobs relying on is Prophet. From 9.1 to 10.4, both the versions of Prophet (1.0.1) and PyStan (2.19.1.1) haven't changed, however...
- 734 Views
- 0 replies
- 0 kudos
- 541 Views
- 0 replies
- 0 kudos
How to check unlinked databricks configs which are not used in any shards
We have a limit of deploying databricks shards and there are few shards that are unused. How can we check and remove these unlinked databricks shards using api calls
- 541 Views
- 0 replies
- 0 kudos
- 8060 Views
- 8 replies
- 7 kudos
Resolved! How to use python packages from `sys.path` ( in some sort of "edit-mode") which functions on workers too?
The help of `dbx sync` states that ```for the imports to work you need to update the Python path to include this target directory you're syncing to```This works quite well whenever the package is containing only driver-level functions. However, I ran...
- 8060 Views
- 8 replies
- 7 kudos
- 7 kudos
Hi @Davide Cagnoni. Please see my answer to this post https://community.databricks.com/s/question/0D53f00001mUyh2CAC/limitations-with-udfs-wrapping-modules-imported-via-repos-filesI will copy it here for you:If your notebook is in the same Repo as t...
- 7 kudos
- 1574 Views
- 2 replies
- 2 kudos
Why is GPU accelerated node much slower than CPU node for training a random forest model on databricks?
I have a dataset about 5 million rows with 14 features and a binary target. I decided to train a pyspark random forest classifier on Databricks. The CPU cluster I created contains 2 c4.8xlarge workers (60GB, 36core) and 1 r4.xlarge (31GB, 4core) driv...
- 1574 Views
- 2 replies
- 2 kudos
- 2 kudos
In many cases, you need to adjust your code to utilize GPU.
- 2 kudos
- 2333 Views
- 4 replies
- 4 kudos
Catch-up Structured Stream hangs on last step of write job to delta sync using toTable
I'm running databricks version 10.4 on gcp. I'm running a structured stream trying to process historical files in a delta table on gcp cloud storage. This source delta table is big but maintained with OPTIMIZE.The stream repartitions which seems to b...
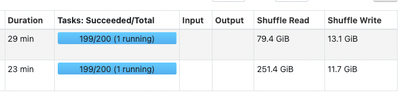
- 2333 Views
- 4 replies
- 4 kudos
- 4 kudos
Hi @Dwight Branscombe Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you....
- 4 kudos
- 1271 Views
- 2 replies
- 3 kudos
How to isolate environments for different projects in a single mlflow server?
I am planning to deploy MLFlow server deployed in Azure as a centralised repositories for my machine learning experiments and runs and to store events and artifacts. I would like to have different environments or isolated environments in the same wor...
- 1271 Views
- 2 replies
- 3 kudos
- 3 kudos
Hi @Hemanth Vakacharla Does @Debayan Mukherjee response answer your question? If yes, would you be happy to mark it as best so that other members can find the solution more quickly?We'd love to hear from you.Thanks!
- 3 kudos
- 17036 Views
- 17 replies
- 13 kudos
Resolved! Created nested struct schema SPARK - Schema Jira
Hello guys,I'm using Jira API to return "ISSUES". But to be able to use pyspark I need to create the Dataframe passing in the Schema. But I am not able to create the Schema based on the model below. Would you have any ideas?root |-- expand: string ...
- 17036 Views
- 17 replies
- 13 kudos
- 13 kudos
if columns are missing, that particular data is not present in the json. I am not aware of spark skipping columns when reading json with inferschema. There is an option dropFieldIfAllNull but that is False by default.That makes me think: you might ...
- 13 kudos
- 1144 Views
- 2 replies
- 0 kudos
Utilize databricks compute for model training from Pycharm IDE
I like to train my machine learning model from Pycharm IDE. But I want to utilize databricks cluster as compute power to speed up the training. Is it possible
- 1144 Views
- 2 replies
- 0 kudos
- 0 kudos
Hi @Suvikram Yerramilli Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from yo...
- 0 kudos
- 864 Views
- 2 replies
- 1 kudos
Feature Store best practice: refactoring notebook
Hello, I have a question about best practice regarding registering a feature in Databricks feature store.Lets say that I create and register features during the EDA or experiment phase of a ML project. Later the model is moving to production stage ...
- 864 Views
- 2 replies
- 1 kudos
- 1 kudos
Hi @Willis Harding Does @Kaniz Fatma response answer your question? If yes, would you be happy to mark it as best so that other members can find the solution more quickly?We'd love to hear from you.Thanks!
- 1 kudos
- 1407 Views
- 1 replies
- 0 kudos
Resolved! Issue logging into my account
Hello, I need assistance accessing my account in data bricks community edition. I got an error that my account was locked due to recent suspicious activity. I tried to reset my password but did not get an email with password change instructions. Than...
- 1407 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @Juan Ochoa , Thank you for reaching out, and we’re sorry to hear about this log-in issue! We have this Community Edition login troubleshooting post on Community. Please take a look, and follow the troubleshooting steps. If the steps do not resol...
- 0 kudos
- 1412 Views
- 3 replies
- 1 kudos
Expose low latency APIs from Deltalake for mobile apps and microservices
My company is using Deltalake to extract customer insights and run batch scoring with ML models. I need to expose this data to some microservices thru gRPC and REST APIs. How to do this? I'm thinking to build Spark pipelines to extract teh data, stor...
- 1412 Views
- 3 replies
- 1 kudos
- 1 kudos
Hi @John Capplefield Gentle follow-up, please let us know if you need further help on this.
- 1 kudos
- 1024 Views
- 1 replies
- 2 kudos
CountVectorizer no longer works through Azure ML
Hello. I am trying to use the CountVectorizer module as part of our feature engineering. It works on a Databricks notebook directly, but when I try to run the code through Azure with the databricks connection, it throws an error. This isn't the first...
- 1024 Views
- 1 replies
- 2 kudos
- 2 kudos
Hi @Danny Siu Please check that you are using the latest dbconnect version corresponding to the DBR version that you are using in the databricks cluster.You can check the latest dbr version here: https://pypi.org/project/databricks-connect/#history
- 2 kudos
- 1015 Views
- 1 replies
- 0 kudos
Is Model Serving REST API available?
This is mentioned in:https://learn.microsoft.com/en-us/azure/databricks/mlflow/create-manage-serverless-model-endpointswith api call example, while in:https://learn.microsoft.com/en-us/answers/questions/892678/how-to-enable-databricks-model-serving-w...
- 1015 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @Thou Mather , Did you get a chance to go through this doc?
- 0 kudos
- 1563 Views
- 2 replies
- 2 kudos
Resolved! Failure in mlflow.spark.load_model : Random Forrest pretrained model
model = mlflow.spark.load_model(model_uri=f"models:/{model_name}/{model_version}")Log:An error occurred while calling o2861.load.: org.apache.spark.SparkException: Job aborted due to stage failure: Task 4 in stage 4599.0 failed 4 times, most recent f...
- 1563 Views
- 2 replies
- 2 kudos
- 2 kudos
Hi @Ashraf Khan Did you get a chance to look into Sean's response. Please let us know if you need more help on this.
- 2 kudos
Connect with Databricks Users in Your Area
Join a Regional User Group to connect with local Databricks users. Events will be happening in your city, and you won’t want to miss the chance to attend and share knowledge.
If there isn’t a group near you, start one and help create a community that brings people together.
Request a New Group-
Academy
1 -
Access
4 -
Access control
3 -
Access Data
2 -
AccessKeyVault
1 -
Account
4 -
ADB
2 -
Adf
1 -
ADLS
2 -
AI Summit
4 -
Airflow
1 -
Amazon
2 -
Apache
1 -
Apache spark
3 -
API
5 -
APILimit
1 -
Artifacts
1 -
Audit
1 -
Autoloader
6 -
Autologging
2 -
Automation
2 -
Automl
21 -
AWS
7 -
Aws databricks
1 -
Aws s3
2 -
AWSSagemaker
1 -
Azure
32 -
Azure active directory
1 -
Azure blob storage
2 -
Azure data factory
1 -
Azure data lake
1 -
Azure Data Lake Storage
3 -
Azure data lake store
1 -
Azure databricks
32 -
Azure DevOps
2 -
Azure event hub
1 -
Azure key vault
1 -
Azure sql database
1 -
Azure Storage
2 -
Azure synapse
1 -
Azure Unity Catalog
1 -
Azure vm
1 -
AzureML
2 -
Bar
1 -
Best practice
6 -
Best Practices
8 -
Best Way
1 -
Beta
1 -
Better Way
1 -
Bi
1 -
BI Integrations
1 -
BI Tool
1 -
Billing and Cost Management
1 -
Blob
1 -
Blog
1 -
Blog Post
1 -
Broadcast variable
1 -
Bug
2 -
Bug Report
2 -
Business Intelligence
1 -
Catalog
3 -
CatalogDDL
1 -
CatalogPricing
1 -
Centralized Model Registry
1 -
Certification
2 -
Certification Badge
1 -
Change
1 -
Change Logs
1 -
Chatgpt
2 -
Check
2 -
CHUNK
1 -
CICD
3 -
Classification Model
1 -
Cli
1 -
Clone
1 -
Cloud Storage
1 -
Cluster
10 -
Cluster Configuration
2 -
Cluster management
5 -
Cluster policy
1 -
Cluster Start
1 -
Cluster Tags
1 -
Cluster Termination
2 -
Clustering
1 -
ClusterMemory
1 -
Clusters
5 -
ClusterSpecification
1 -
CNN HOF
1 -
Code
3 -
Column names
1 -
Community
4 -
Community Account
1 -
Community Edition
1 -
Community Edition Password
1 -
Community Members
1 -
Company Email
1 -
Concat Ws
1 -
Conda
1 -
Condition
1 -
Config
1 -
Configure
3 -
Confluent Cloud
1 -
Connect
1 -
Container
2 -
ContainerServices
1 -
Control Plane
1 -
ControlPlane
1 -
Copy
2 -
Copy into
2 -
CosmosDB
1 -
Cost
1 -
Courses
2 -
CSV
6 -
Csv files
1 -
DAIS2023
1 -
Dashboards
1 -
Data
9 -
Data Engineer Associate
1 -
Data Engineer Certification
1 -
Data Explorer
1 -
Data Ingestion
2 -
Data Ingestion & connectivity
11 -
Data Quality
1 -
Data Quality Checks
1 -
Data Science
12 -
Data Science & Engineering
2 -
databricks
5 -
Databricks Academy
3 -
Databricks Account
1 -
Databricks AutoML
9 -
Databricks Cluster
3 -
Databricks Community
5 -
Databricks community edition
4 -
Databricks connect
1 -
Databricks dbfs
1 -
Databricks Environment
1 -
Databricks Feature Store
1 -
Databricks JDBC
1 -
Databricks Job
1 -
Databricks jobs
1 -
Databricks Lakehouse
1 -
Databricks Lakehouse Platform Accreditation
1 -
Databricks Mlflow
4 -
Databricks Model
2 -
Databricks notebook
10 -
Databricks ODBC
1 -
Databricks Platform
1 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repos
2 -
Databricks Repos Api
1 -
Databricks Runtime
9 -
Databricks SQL
8 -
Databricks SQL Permission Problems
1 -
Databricks Terraform
1 -
Databricks Training
2 -
Databricks Unity Catalog
1 -
Databricks V2
1 -
Databricks version
1 -
Databricks Workflow
2 -
Databricks Workflows
1 -
Databricks workspace
2 -
Databricks-connect
1 -
DatabricksContainer
1 -
DatabricksJobs
2 -
DatabricksML
6 -
Dataframe
3 -
Datalake
1 -
DataLakeGen1
1 -
DataSharing
1 -
Datatype
1 -
DataVersioning
1 -
Date
1 -
Date Column
1 -
Dateadd
1 -
DB Notebook
1 -
DB Runtime
1 -
DBFS
5 -
DBFS Rest Api
1 -
Dbt
1 -
Dbu
1 -
Dbutils
2 -
Dbx
2 -
DDL
1 -
DDP
1 -
Dear Community
1 -
DecisionTree
1 -
DecisionTreeClasifier
1 -
Deep learning
4 -
Default Location
1 -
Delete
1 -
Delt Lake
4 -
Delta
24 -
Delta lake table
1 -
Delta Live
1 -
Delta Live Tables
6 -
Delta log
1 -
Delta Sharing
3 -
Delta table
9 -
Delta-lake
1 -
Deploy
1 -
DESC
1 -
Details
1 -
Dev
1 -
Devops
1 -
Df
1 -
Difference
2 -
Different Notebook
1 -
Different Parameters
1 -
DimensionTables
1 -
Directory
3 -
Disable
1 -
Display
1 -
Distribution
1 -
DLT
6 -
DLT Pipeline
3 -
Docker
1 -
Docker image
3 -
Documentation
4 -
Dolly
5 -
Dolly Demo
2 -
Download
2 -
EC2
1 -
Emr
2 -
Endpoint
2 -
Ensemble Models
1 -
Environment Variable
1 -
Epoch
1 -
Error
18 -
Error Code
2 -
Error handling
1 -
Error log
2 -
Error Message
4 -
ETL
2 -
Eventhub
1 -
Exam
1 -
Example
1 -
Excel
2 -
Exception
3 -
Experiments
4 -
External Sources
1 -
Extract
1 -
Fact Tables
1 -
Failure
2 -
Feature
9 -
Feature Lookup
2 -
Feature Store
48 -
Feature Store API
2 -
Feature Store Table
1 -
Feature Table
6 -
Feature Tables
4 -
Features
2 -
FeatureStore
2 -
File
5 -
File Path
2 -
File Size
1 -
Files
2 -
Fine Tune Spark Jobs
1 -
Forecasting
2 -
Forgot Password
2 -
Garbage Collection
1 -
Garbage Collection Optimization
1 -
GCP
4 -
Gdal
1 -
Git
3 -
Github
2 -
Github actions
2 -
Github Repo
2 -
Gitlab
1 -
GKE
1 -
Global Init Script
1 -
Global init scripts
4 -
Google
1 -
Governance
1 -
Gpu
5 -
Graphviz
1 -
Hadoop
1 -
Help
5 -
Hi
1 -
Horovod
1 -
Html
1 -
Hyperopt
4 -
Hyperparameter Tuning
2 -
Iam
1 -
Image
3 -
Image Data
1 -
Import
2 -
Industry Experts
1 -
Inference Setup Error
1 -
INFORMATION
1 -
Init script
3 -
Input
1 -
Insert
1 -
Instance Profile
1 -
Int
2 -
Interactive cluster
1 -
Internal error
1 -
INVALID STATE
1 -
Invalid Type Code
1 -
IP
1 -
Ipython
1 -
Ipywidgets
1 -
Jar
1 -
Java
2 -
JDBC Connections
1 -
Jdbc driver
1 -
Jira
1 -
Job
4 -
Job Cluster
1 -
Job Parameters
1 -
Job Runs
1 -
JOBS
5 -
Jobs & Workflows
6 -
Join
1 -
Jsonfile
1 -
Jupyternotebook
2 -
K-means
1 -
K8s
1 -
Kafka consumer
1 -
Kedro
1 -
Key Management
1 -
Kinesis
1 -
Lakehouse
1 -
Large Datasets
1 -
Latest Version
1 -
Learning
1 -
Libraries
2 -
Library
3 -
LightGMB
1 -
Limit
3 -
Linear regression
1 -
List
1 -
LLM
3 -
LLMs
14 -
Local computer
1 -
Local Machine
1 -
Log Model
2 -
Logging
1 -
Login
1 -
Logistic regression
1 -
LogPyfunc
1 -
LogRuns
1 -
Logs
1 -
Long Time
2 -
Low Latency APIs
2 -
LTS
3 -
LTS ML
3 -
Machine
3 -
Machine Learning
25 -
Machine Learning Associate
1 -
Managed Table
1 -
Maven
1 -
Max Retries
1 -
Maximum Number
1 -
Medallion Architecture
1 -
Memory
3 -
Merge
4 -
Merge Into
1 -
Metadata
1 -
Metrics
3 -
Microsoft
1 -
Microsoft azure
1 -
ML
17 -
ML Lifecycle
4 -
ML Model
4 -
ML Pipeline
2 -
ML Practioner
3 -
ML Runtime
1 -
MLEndPoint
1 -
MlFlow
75 -
MLflow API
5 -
MLflow Artifacts
2 -
MLflow Experiment
6 -
MLflow Experiments
3 -
Mlflow Model
10 -
Mlflow project
4 -
Mlflow registry
3 -
Mlflow Run
1 -
Mlflow Server
5 -
MLFlow Tracking Server
3 -
MLModel
1 -
MLModelRealtime
1 -
MLModels
2 -
Mlops
6 -
Model
32 -
Model Deployment
4 -
Model Lifecycle
6 -
Model Loading
2 -
Model Monitoring
1 -
Model registry
5 -
Model Serving
31 -
Model Serving Cluster
2 -
Model Serving REST API
6 -
Model Size
2 -
Model Training
2 -
Model Tuning
1 -
Model Version
1 -
Models
8 -
Module
3 -
Modulenotfounderror
1 -
MongoDB
1 -
Monitoring and Visibility
1 -
Mount Point
1 -
Mounts
1 -
Multi
1 -
Multiline
1 -
Multiple users
1 -
Nested
1 -
New
2 -
New Cluster
1 -
New Feature
1 -
New Features
1 -
New Workspace
1 -
Nlp
4 -
Note
1 -
Notebook
6 -
Notebook Context
1 -
Notebooks
5 -
Notification
2 -
Object
3 -
Object Type
1 -
Odbc
1 -
Onboarding
1 -
Online Feature Store Table
1 -
OOM Error
1 -
Open source
2 -
Open Source MLflow
4 -
Optimization
2 -
Optimize
1 -
Optimize Command
1 -
OSS
3 -
Overwatch
1 -
Overwrite
2 -
Packages
2 -
Pandas
3 -
Pandas dataframe
1 -
Pandas udf
4 -
Pandas_udf
1 -
Parallel
1 -
Parallel processing
1 -
Parallel Runs
1 -
Parallelism
1 -
Parameter
2 -
PARAMETER VALUE
2 -
Partition
1 -
Partner Academy
1 -
Password
1 -
Path
1 -
Pending State
2 -
Performance
2 -
Performance Tuning
1 -
Permission
1 -
Personal access token
2 -
Photon
2 -
Photon Engine
1 -
Pickle
1 -
Pickle Files
2 -
Pip
2 -
Pipeline Model
1 -
Points
1 -
Possible
1 -
Postgres
1 -
Presentation
1 -
Pricing
2 -
Primary Key
1 -
Primary Key Constraint
1 -
PROBLEM
2 -
Production
2 -
Progress bar
2 -
Proven Practice
4 -
Proven Practices
2 -
Public
2 -
Pycharm IDE
1 -
Pyfunc Model
2 -
Pymc
1 -
Pymc3
1 -
Pymc3 Models
2 -
PyPI
1 -
Pyspark
6 -
Pyspark Dataframe
1 -
Python
22 -
Python API
1 -
Python Code
1 -
Python Error
1 -
Python Function
3 -
Python Libraries
1 -
Python notebook
2 -
Python Packages
1 -
Python Project
1 -
Python script
1 -
Python Task
1 -
Pytorch
3 -
Query
2 -
Question
2 -
R
6 -
R Shiny
1 -
Randomforest
2 -
Rate Limits
1 -
Reading-excel
2 -
Redis
2 -
Region
1 -
Remote RPC Client
1 -
Repos
1 -
Rest
1 -
Rest API
15 -
REST Endpoint
2 -
RESTAPI
1 -
Result
1 -
Rgeos Packages
1 -
Run
3 -
Runtime
2 -
Runtime 10.4 LST ML
1 -
Runtime update
1 -
S3
1 -
S3bucket
2 -
Sagemaker
1 -
Salesforce
1 -
SAP
1 -
Scalability
1 -
Scalable Machine
2 -
Schema
4 -
Schema evolution
1 -
Score Batch Support
1 -
Script
1 -
SDLC
1 -
Search
1 -
Search Runs
1 -
Secret scope
1 -
Secure Cluster Connectiv
1 -
Security
2 -
Security Exception
1 -
Self Service Notebooks
1 -
Server
1 -
Serverless
1 -
Serverless Inference
1 -
Serverless Real
1 -
Service Application
1 -
Service principal
1 -
Serving
1 -
Serving Status Failed
1 -
Set
1 -
Sf Username
1 -
Shap
2 -
Similar Issue
1 -
Similar Support
1 -
Simple Spark ML Model
1 -
Sin Cosine
1 -
Size
1 -
Sklearn
1 -
SKLEARN VERSION
1 -
Slow
1 -
Small Scale Experimentation
1 -
Source Table
1 -
Spark
14 -
Spark config
1 -
Spark connector
1 -
Spark Daatricks
1 -
Spark Error
1 -
Spark Means
1 -
Spark ML's CrossValidator
1 -
Spark MLlib
2 -
Spark MLlib Models
1 -
Spark Model
1 -
Spark Optimization
1 -
Spark Pandas Api
1 -
Spark Pipeline Model
1 -
Spark streaming
1 -
Spark ui
1 -
Spark Version
2 -
Spark-submit
1 -
Sparkml
1 -
SparkML Models
2 -
Sparknlp
3 -
SparkNLP Model
1 -
Sparktrials
1 -
Split Data
1 -
Spot
1 -
SQL
19 -
SQL Editor
1 -
SQL Queries
1 -
Sql query
1 -
SQL Visualisations
1 -
SQL Visualizations
1 -
Stage failure
2 -
Standard
2 -
StanModel
1 -
Storage
3 -
Storage account
1 -
Storage Space
1 -
Store Import Error
1 -
Store MLflow
1 -
Store Secret
1 -
Stream
2 -
Stream Data
1 -
Streaming
1 -
String
3 -
Stringindexer
1 -
Structtype
1 -
Structured streaming
2 -
Study Material
1 -
Substantial Performance Issues
1 -
Successful Runs
1 -
Summit22
3 -
Summit23
2 -
Support
1 -
Support Team
1 -
Synapse
1 -
Synapse ML
1 -
Table
4 -
Table access control
1 -
Tableau
1 -
Tables
3 -
Tabular Models
1 -
Task
1 -
Temporary View
1 -
Tensor flow
1 -
Tensorboard
1 -
Tensorflow Distributor
1 -
TensorFlow Model
2 -
Terraform
1 -
Test
1 -
Test Dataframe
1 -
Text Column
1 -
TF Model
1 -
TF SummaryWriter
1 -
TF SummaryWriter Flush
1 -
Threading Lock
1 -
TID
4 -
Time
1 -
Time-Series
1 -
Timeseries
1 -
Timestamps
1 -
TODAY
1 -
Tracking Server
1 -
Training
6 -
Transaction Log
1 -
Trying
1 -
Tuning
2 -
Type
1 -
Type Changes
1 -
UAT
1 -
UC
1 -
Udf
6 -
Ui
1 -
Unexpected Error
1 -
Unity Catalog
12 -
Unrecognized Arguments
1 -
Urgent Question
1 -
Use
5 -
Use Case
2 -
Use cases
1 -
User and Group Administration
1 -
Using MLflow
1 -
UTC
2 -
Utils.environment
1 -
Uuid
1 -
Val File Path
1 -
Validate ML Model
2 -
Values
1 -
Variable
1 -
Variable Explanations
1 -
Vector
1 -
Version
1 -
Version Information
1 -
Versioncontrol
1 -
Versioning
1 -
View
1 -
Visualization
2 -
WARNING
1 -
Web App Azure Databricks
1 -
Web ui
1 -
Weekly Release Notes
2 -
weeklyreleasenotesrecap
2 -
Whl
1 -
Wildcard
1 -
Worker Nodes
1 -
Workflow
2 -
Workflow Jobs
1 -
Workspace
2 -
Workspace Region
1 -
Write
1 -
Writing
1 -
XGBModel
2 -
Xgboost
2 -
Xgboost Model
2 -
Yesterday Afternoon
1 -
Z-ordering
1 -
Zorder
1
- « Previous
- Next »
| User | Count |
|---|---|
| 89 | |
| 39 | |
| 36 | |
| 25 | |
| 25 |