Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Warehousing & Analytics
Engage in discussions on data warehousing, analytics, and BI solutions within the Databricks Community. Share insights, tips, and best practices for leveraging data for informed decision-making.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Warehousing & Analytics
- Re: Misleading UNBOUND_SQL_PARAMETER even though p...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-04-2024 12:01 AM
Hello. Please forgive me if this is not the right place to ask, but I'm having issues with databricks' statement execution api. I'm developing Haskell client for this api.
I managed to implement most of it, but I'm running into issues with using named parameters to interpolate values into queries.
The documentation says that I can use named parameter markers in combination with IDENTIFIER to interpolate table names into queries.
This is however not working in all cases. Specifically I'm getting a very misleading error in the following case, when I'm interpolating table identifier in an INSERT statement. I'm running the following request (using linux `curl` command to illustrate the issue)
curl --request POST \
https://WORKSPACE_ID_REDACTED.cloud.databricks.com/api/2.0/sql/statements/ \
--header "Authorization: Bearer DATABRICKS_TOKEN_REDACTED" \
--header "Content-Type: application/json" \
--data '{
"warehouse_id": "WAREHOUSE_ID_REDACTED",
"statement": "INSERT INTO IDENTIFIER(:mytable) VALUES (:name, :age)",
"parameters": [{"name": "name", "value": "jan"},{"name": "age", "value": "10"},{"name": "mytable", "value": "z_jan_hrcek.test.person"}]
}'
Actual behavior:
I get an error response like this:
{"statement_id":"01eed9f9-13c6-1abf-ad15-22647b4a619c","status":{"state":"FAILED","error":{"error_code":"BAD_REQUEST","message":"[UNBOUND_SQL_PARAMETER] Found the unbound parameter: name. Please, fix `args` and provide a mapping of the parameter to a SQL literal.; line 1 pos 41"}}}This is misleading, because it states I'm not providing `name` parameter, even though you can see I am actually providing the value for this parameter in the request.
Expected behavior:
- all supplied parameters should be interpolated into the query
OR
* better error message to make it clear what the issue is (is it that interpolating table name into INSERT queries is not supported?)
Interestingly, if I hard-code the table name into the query, everything works as expected:
curl --request POST \
https://dbc-6ce34a66-aae7.cloud.databricks.com/api/2.0/sql/statements/ \
--header "Authorization: Bearer dapic78c5812b28d77c2c768c4520cf6c7c8" \
--header "Content-Type: application/json" \
--data '{
"warehouse_id": "77d7c1940bb93e75",
"statement": "INSERT INTO z_jan_hrcek.test.person VALUES (:name, :age)",
"parameters": [{"name": "name", "value": "jan"},{"name": "age", "value": "10"}]
}'
# ^ This succeeds, and 1 row is insterted into the table
But for my use case I need the ability to specify table name dynamically and ideally use parameter interpolation to help me prevent SQL injection.


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-01-2025 03:32 AM
Unfortunately the advice with `${...}` doesn't really apply to queries submitted via statement execution api that this issue is about. However it seems that the original issue has been resolved in the meantime 😊
16 REPLIES 16
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-07-2024 03:35 AM
Thanks for the reply, but I don't find this (LLM generated?) reply very helpful 😢
None of the troubleshooting tips helps:
- Check Parameter Names: don't you see the example code? You can check for yourself that names of params in the query correspond to the names of args in parameters list
- Quotes Around IDENTIFIER: The identifier has to contain the table name placeholder. It can't be quoted, otherwise parameter interpolation doesn't work.
- API Version Compatibility: the api version IS in the URL /2.0/ as you can see in my examples
- Permissions and Warehouse Configuration: This can't be the problem, because everything works when I hardcode the table
- Try Unnamed Parameters: unnamed parameters are not supported in statement execution api based on the documentation (https://docs.databricks.com/api/workspace/statementexecution/executestatement#parameters😞
currently, positional parameters denoted by a ? marker are not supported by the Databricks SQL Statement Execution API.
What would be more helpful is if you could point me to some github repo/issue tracker where I can report this issue as it seems to be a problem with how the api backend is implemented.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-07-2024 06:20 AM
Ok, I thing I found what's behind this.
This seems to be a bug in spark itself.
Here's how I was able to reproduce it in spark-shell running in docker container:
https://gist.github.com/jhrcek/49386004a9a47172649158af288106f4
I think it's best if I just report it in spark issue tracker.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-20-2024 07:28 AM
I just wanted to note that this is still an issue in Databricks notebooks. If you do run into it, you may be able to work around it by changing the compute resource that is associated with the notebook.
Here is a simple reproduction I ran in a cell in a notebook (added a widget for var1 as well). Using a SQL warehouse compute resource it succeeds, using an All-purpose compute resource causes it to fail.
--Test case 1: succeeds when executed with All-purpose compute or with SQL warehouse
SELECT * FROM IDENTIFIER('information_schema.columns') LIMIT 1;
--Test case 2: created widget in notebook with name var1, specify value of "columns".
-- when executed with SQL warehouse: query succeeds
-- when executed with All-purpose compute: query fails - [UNBOUND_SQL_PARAMETER] Found the unbound parameter: var1.
SELECT * FROM IDENTIFIER('information_schema.'||:var1) LIMIT 1;Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-29-2024 12:18 PM
Following up on my above note, it is not an issue. There was syntax change for parameters, so based on the Databricks Runtime version of the compute used, you may need to change how the query does parameters.
Old syntax: ${var1}
New syntax: :var1
Example:
--below works fine with All-purpose compute using version 15.3
SELECT * FROM IDENTIFIER('system.information_schema.'||:var1) LIMIT 1;
--below fails ("unbound parameter") with All-purpose compute using version 14.3
SELECT * FROM IDENTIFIER('system.information_schema.'||:var1) LIMIT 1;
--below succeeds with All-purrpose compute using version 14.3
SELECT * FROM IDENTIFIER('system.information_schema.${var1}') LIMIT 1;
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-18-2025 04:22 AM
Saved my life in here!! Tkss for the explanation
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-29-2024 09:12 PM
@eriodega please read my last answer above.
The IDENTIFIER(:param) works fine when you use it in some types of queries (like SELECT), but it doesn't work in other types of statements (e.g. INSERT INTO IDENTIFIER(:mytable) ...).
Here's a reproducer that demonstrates the issue is still present in the latest version of spark:
https://gist.github.com/jhrcek/49386004a9a47172649158af288106f4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-30-2024 06:09 AM
@jhrcekagreed, your original issue is still a bug. I created a support case with Databricks Support for it, we'll see what they say.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-03-2024 06:45 AM
I'm new to all this Databricks stuff and I've immediately run into this "UNBOUND_SQL_PARAMETER" error after trying to be "fancy" with my parameters (query-bound).
My workaround after multiple trial and errors was to switch from the newer "Named parameter marker syntax" (i.e., :parameter_name) to original(?) "Mustache parameter syntax" (i.e., {{parameter_name}}). This worked for me.
Details:
Query Editor
A "simple" SELECT with "Query Based Dropdown" parameter.
Using "Named parameter marker syntax" leads to following error:
[UNBOUND_SQL_PARAMETER] Found the unbound parameter: CompanyCode. Please, fix `args` and provide a mapping of the parameter to either a SQL literal or collection constructor functions such as `map()`, `array()`, `struct()`. SQLSTATE: 42P02; line 116, pos 21
Simple "text"/"number" type of parameters work with either syntax.
It's clearly a bug but at this point I don't have enough knowledge to confidently point to culprit.
Hope this helps somebody.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-03-2024 07:22 AM
FYI, I just tested it again yesterday, and with the new runtime version 15.4 LTS, the bug is fixed.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-28-2024 08:23 AM
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-08-2024 04:44 AM
I am using the runtime version 15.4, but the issue is still exists for the INSERT statement
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-28-2024 08:45 AM
@vivilyhere's a repro:
%scala
val tableName = "delta.`/Volumes/<YOUR_PATH_HERE>/delete_me_test_table1`"
spark.sql(
"INSERT INTO IDENTIFIER(:table1)(id,name) VALUES(1,'alice');",
Map("table1" -> tableName)
).show()
//above succeeds.
spark.sql(
"INSERT INTO IDENTIFIER(:table1)(id,name) VALUES(1,:name);",
Map("table1" -> tableName, "name" -> "bob")
).show()
//above fails with 14.3 compute, succeeds with 15.4 ML compute
Note: this is the SQL I used elsewhere to create the table:
CREATE TABLE delta.`/Volumes/<YOUR_PATH_HERE>/delete_me_test_table1`
SELECT
-1 as id,
'initial' as name;
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-04-2024 07:52 AM
Not sure why but I still get the error, even with a simple select when trying to run parametrized sql in a notebook cell:
This fails:
%python
table_name = "my_table"
%sql
select org_id
from identifier(:table_name)
While this succeeds:
%sql
select org_id
from "my_table"
(BTW I have been unable to post an answer since last week - I keep getting a "Maximum flood limit reached" and only managed to by-pass it by removing code formatting)
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-31-2025 01:44 PM - edited 03-31-2025 01:46 PM
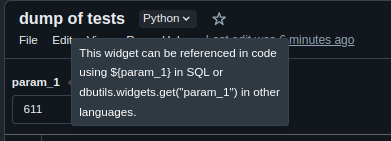
Hi! I came across a similar error. Here's my solution:
When you hover over the widget, it says "This widget can be referenced in code using ${your_param} in SQL or dbutils.widgets.get("your_param") in other languages." I didn't find anything like that in the documentation. lol
So, yeah, try to replace :your_param for ${your_param}. 🙂 Hope it helps.
Announcements





{kind=link}
Related Content
- The Open-Weight Revolution: A Game Changer for Our LLM Cost Optimization Odyssey in Generative AI
- UI sends empty managed_identity_id, breaks storage credential creation with system-assigned Access in Data Governance
- ODBC Parameterization issue (Basic .NET) in Data Engineering
- Calling a function with parameters via Spark ODBC driver in Data Engineering
- Using Parameters in EXECUTE IMMEDIATE on Databricks SQL 2025.15 not working in Warehousing & Analytics