- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-18-2023 05:02 AM
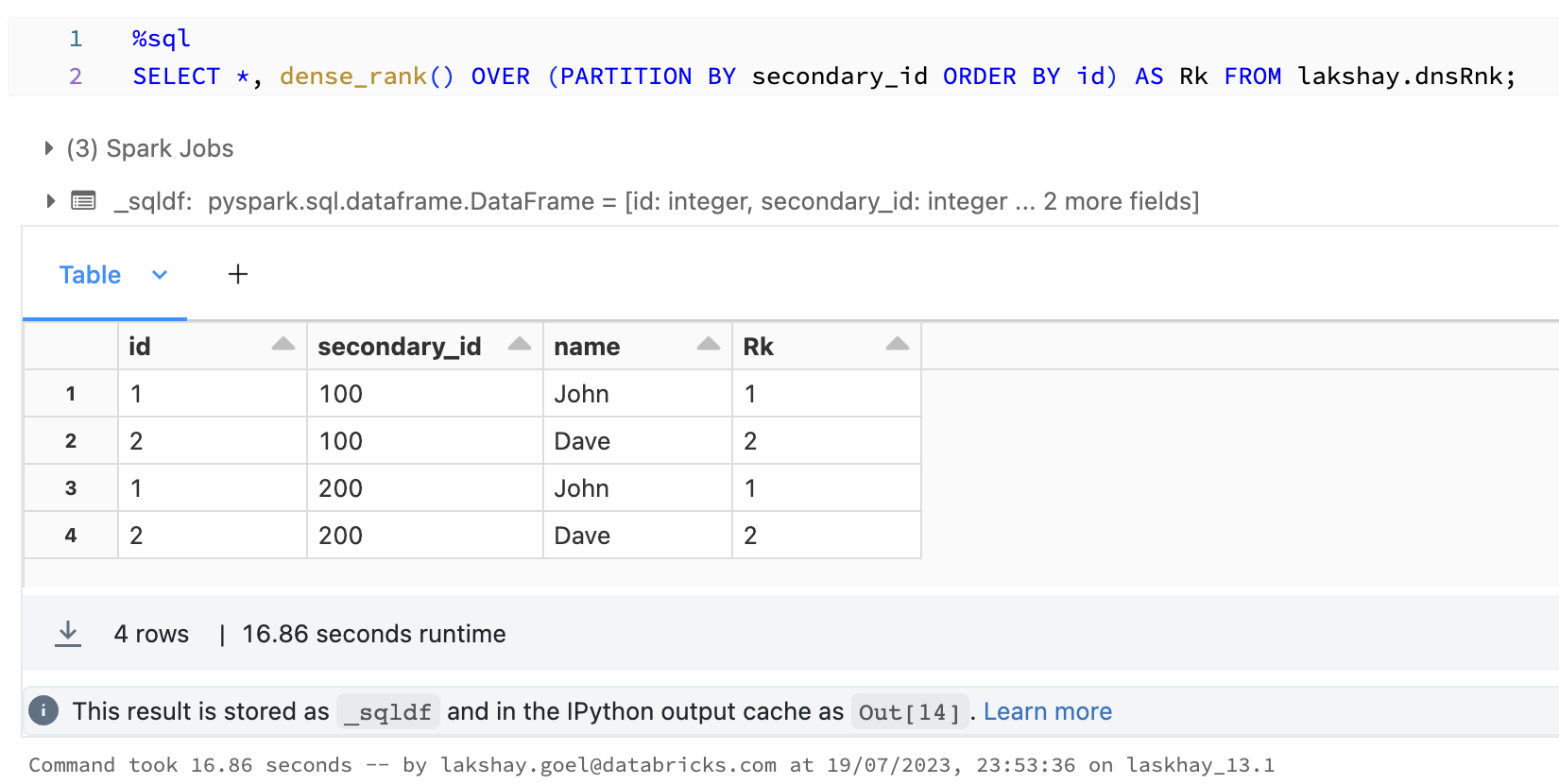
I have the case of deduplicating data source over specific business key using dense_rank function. Currently the data source does not have any duplicates, so the function should return 1 in all cases. The issue is that dense rank does not return proper integer, although data type is of integer:
- When filtering rank function equal to 1, it gives me "random" number of records. Most of dense_rank values with display values of 1 are getting dropped
- When filtering rank < 1.1 it gives me the same results as above
- When filtering rank > 0.9 it gives me the expected amount of rows
- When casting rank function to double and then filtering it as equal to 1, it gives me expected number of rows
It happens on databricks runtime 13.1, so I am assuming spark 3.4 has this issue. It works with no problem with runtime 12.2
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-18-2023 05:13 AM
Could you share a code snippet of how you are applying the rank function?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-18-2023 05:45 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-19-2023 11:27 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-19-2023 12:37 PM
Hey @Łukasz
Thanks for reporting.
As I see Spark 3.4.0 introduced an improvement that looks to be the cause for this issue.
Improvement: https://issues.apache.org/jira/browse/SPARK-37099
Similar Bug: https://issues.apache.org/jira/browse/SPARK-44448
This improvement [SPARK-37099] is included as part of DBR 13.1: https://docs.databricks.com/release-notes/runtime/13.1.html
That is the reason you are seeing this in DBR 13.1
As I have verified internally this seems to be fixed in DBR 13.1. I would request you to test it again once and let us know.
Saikrishna Pujari
Sr. Spark Technical Solutions Engineer, Databricks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-20-2023 12:57 AM
Hello @Saniam
Thanks for answer, I have just tested and it seems to be working fine both in 13.1 and 13.2
On the other note, can you help me understand how the releases are done for spark? The one that you mention is said to be released in 3.5, which should come in new databricks runtime release.
Kind regards,
Łukasz
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-26-2023 08:24 AM
Hey @Łukasz it's because any fixes which are important are backported to older spark versions in DBR, that's the reason you see this fixed in DBR 13.1
Saikrishna Pujari
Sr. Spark Technical Solutions Engineer, Databricks

{kind=link}