Administration & Architecture
327 Posts
I am writing data to cosmos DB using Python & Spark on DatabricksI am getting below error :org.apache.spark.SparkException: Job aborted due to stage failure: Authorized committer (attemptNumber=0, stage=192, partition=105) failed; but task commit suc...
The configs are for cluster:Worker Type & Driver type : Standard_D16ads_v5RUs for Cosmos : 1.5L
I have set up a volume in unity catalog in the format catalog/schema/volume, and granted all permissions to all users on the catalog, schema and volume.From the notebook I can see the /Volumes directory in the root of the file system but am unable to...
Thanks for your comments. The problem turned out to be the compute resource not having unity catalog enabled.
Hi,for some reason Azure Databricks doesn't show History if the data is saved with SparkR (2 in the figure below) or Sparklyr (3), but it does show it with Data Ingestion (0) or with PySpark (1). Is this a known bug or am I doing something wrong? Is ...
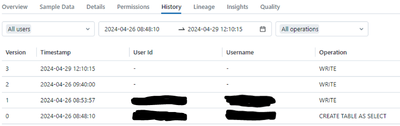
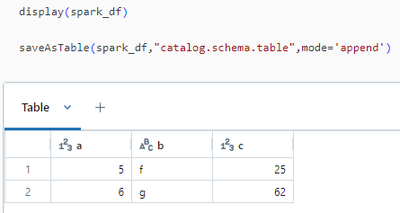
Hi @Sagas, Let’s address your questions regarding Azure Databricks, SparkR, and Sparklyr. History in Azure Databricks: Each operation that modifies a Delta Lake table creates a new table version. You can use history information to audit operation...
I am getting a connect timed out error when attempting to access a sql server. I can successfully ping the server from Databricks. I have used the jdbc connection and the sqlserver included driver and both result in the same error. I have also attemp...
Can you run the following command in a notebook using the same cluster you are using to connect:%sh nc -vz <hostname> <port> This test will confirm us if we are able to communicate with the SQL server by using the port you are defining to connect. If...
Some columns are being dropped when moving to pandas data set. I see part of the dataset, but it does not show when displaying..
Hello Community. I have a user trying to use R and receive the error message illustrated on the attachment. I can't seem to find correct documentation on enabling R on an existing cluster. Would anyone be able to point me in the right direction? Than...
Hello Joaquim,Your issue might be related to the access mode of your cluster which probably has been selected to be Shared Access Mode.Shared cluster only allows Python, SQL and Scala languages, you might need to change the access mode to be Single U...
#20 69.92 ERROR: Could not find a version that satisfies the requirement transformers==4.41.0.dev0 (from versions: 0.1, 2.0.0, 2.1.0, 2.1.1, 2.2.0, 2.2.1, 2.2.2, 2.3.0, 2.4.0, 2.4.1, 2.5.0, 2.5.1, 2.6.0, 2.7.0, 2.8.0, 2.9.0, 2.9.1, 2.10.0, 2.11.0, 3....
Hi @enkefalos-commu , I apologize for the inconvenience you’re facing. Let’s troubleshoot this issue together. Here are some steps you can take: Check Your Python Environment: Ensure that you are using a compatible Python environmentTransformer...
There are multiple tables in the config/metadata table. These tables need to bevalidated for DQ rules.1.Natural Key / Business Key /Primary Key cannot be null orblank.2.Natural Key/Primary Key cannot be duplicate.3.Join columns missing values4.Busine...
Hi @subha2, To dynamically validate the data quality (DQ) rules for tables configured in a metadata-driven system using PySpark, you can follow these steps: Define Metadata for Tables: First, create a metadata configuration that describes the rules ...
Hi Team,We intend to activate the job cluster around the clock. We consider the following parameters regarding cost: - Data volumes - Client SLA for job completion- Starting with a small cluster configuration Please advise on any other options we s...
Hi @Phani1, When configuring a job cluster for 24/7 operation, it’s essential to consider cost, performance, and scalability. Here are some recommendations based on your specified parameters: Data Volumes: Analyze your data volumes carefully. If...
Is there a way to fetch workspace mount points ( mount infos) through REST API or SQL-query ? ( similar to the python API "display(dbutils.fs.mounts())" ) I couldn't find any REST API for the mounts in the official databricks API documentation ( ...
Hi @agarg, As of now, the Databricks REST API does not directly provide a specific endpoint to fetch workspace mount points or mount information. However, you can achieve this by executing SQL queries on Databricks SQL Warehouse using the Databricks ...
Hello All,In my Databricks workflows, I have three tasks configured, with the final task set to run only if the condition "ALL_DONE" is met. During the first deployment, I observed that the dependency "ALL_DONE" was correctly assigned to the last tas...
Hi @Sikki Good day! There was an issue and it was fixed recently. Could you please confirm if you are still facing the issue? Best regards,
I need to execute a .py file in Databricks from a notebook (with arguments which for simplicity i exclude here). For this i am using:%sh script.pyscript.py:from pyspark import SparkContext def main(): sc = SparkContext.getOrCreate() print(sc...
I got it eventually working with a combination of:from databricks.sdk.runtime import *spark.sparkContext.addPyFile("/path/to/your/file")sys.path.append("path/to/your")
Hello, Any plans for supporting Databricks on GDCE or other on private cloud-native stack/HW on premise?Regards, Patrick
Hi @pfpmeijers, As of now, Databricks primarily operates as a unified, open analytics platform for constructing, deploying, sharing, and maintaining enterprise-grade data, analytics, and AI solutions at scale. It seamlessly integrates with cloud stor...
Dear allI have a workflow with 2 tasks : one that does OPTIMIZE, followed by one that does VACUUM. I used a cluster with F32s driver and F64s - 8 workers (auto-scaling enabled). All 8 workers are launched by Databricks as soon as OPTIMIZE starts. As ...

Hi,were you able to get any useful help on this?
Hi!I want to migrate all my databricks related code from one github repo to another. I knew this wouldn't be straight forward. When I copy my code for one DLT, I get the errororg.apache.spark.sql.catalyst.ExtendedAnalysisException: Table 'vessel_batt...
Does cloning take considerably less time then recreating the tables?Can I resume append operations to a cloned table?
| User | Count |
|---|---|
| 1769 | |
| 807 | |
| 459 | |
| 309 | |
| 291 |