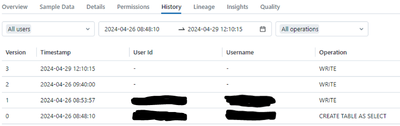
Hi,for some reason Azure Databricks doesn't show History if the data is saved with SparkR (2 in the figure below) or Sparklyr (3), but it does show it with Data Ingestion (0) or with PySpark (1). Is this a known bug or am I doing something wrong? Is ...
Hi @Sagas, Let’s address your questions regarding Azure Databricks, SparkR, and Sparklyr.
History in Azure Databricks:
Each operation that modifies a Delta Lake table creates a new table version. You can use history information to audit operation...
I am getting a connect timed out error when attempting to access a sql server. I can successfully ping the server from Databricks. I have used the jdbc connection and the sqlserver included driver and both result in the same error. I have also attemp...
Can you run the following command in a notebook using the same cluster you are using to connect:%sh
nc -vz <hostname> <port>
This test will confirm us if we are able to communicate with the SQL server by using the port you are defining to connect. If...
There are multiple tables in the config/metadata table. These tables need to bevalidated for DQ rules.1.Natural Key / Business Key /Primary Key cannot be null orblank.2.Natural Key/Primary Key cannot be duplicate.3.Join columns missing values4.Busine...
Hi @subha2, To dynamically validate the data quality (DQ) rules for tables configured in a metadata-driven system using PySpark, you can follow these steps:
Define Metadata for Tables:
First, create a metadata configuration that describes the rules ...
Hi Team,We intend to activate the job cluster around the clock. We consider the following parameters regarding cost: - Data volumes - Client SLA for job completion- Starting with a small cluster configuration Please advise on any other options we s...
Hi @Phani1, When configuring a job cluster for 24/7 operation, it’s essential to consider cost, performance, and scalability.
Here are some recommendations based on your specified parameters:
Data Volumes:
Analyze your data volumes carefully. If...
Hello All,In my Databricks workflows, I have three tasks configured, with the final task set to run only if the condition "ALL_DONE" is met. During the first deployment, I observed that the dependency "ALL_DONE" was correctly assigned to the last tas...
I need to execute a .py file in Databricks from a notebook (with arguments which for simplicity i exclude here). For this i am using:%sh script.pyscript.py:from pyspark import SparkContext
def main():
sc = SparkContext.getOrCreate()
print(sc...
I got it eventually working with a combination of:from databricks.sdk.runtime import *spark.sparkContext.addPyFile("/path/to/your/file")sys.path.append("path/to/your")
Dear allI have a workflow with 2 tasks : one that does OPTIMIZE, followed by one that does VACUUM. I used a cluster with F32s driver and F64s - 8 workers (auto-scaling enabled). All 8 workers are launched by Databricks as soon as OPTIMIZE starts. As ...
Hi!I want to migrate all my databricks related code from one github repo to another. I knew this wouldn't be straight forward. When I copy my code for one DLT, I get the errororg.apache.spark.sql.catalyst.ExtendedAnalysisException: Table 'vessel_batt...
Hi,We tried Delta sharing to PBI which worked fine, But facing issues while trying to apply row, column level filtering or data masking. It fails with error that its not supported.Can anyone please confirm, if delta sharing with masking rules works w...
Hi @Anshul_DBX good day!
The issue you are encountering is due to a limitation in Delta Sharing. As per the provided information, Delta Sharing does not support row-level security or column masks. This means that you cannot apply row and column level...
HiI am facing issues when deploying work flows to different environment. The same works for Notebooks and Scripts, when deploying the work flows, it failed with "Authorization Failed. Your token may be expired or lack the valid scope". Anything shoul...
Hi Sree, Good day!
Looking at the error message it seems like the token is expired. Could you please check if your PAT Token is valid? Have you created the PAT Token for the workspace that you are integrating with?
Regards,
Yesh
I was exploring on unity catalog option on Databricks premium workspace.I understood that i need to create storage account credentials and external connection in workspace.Later, i can access the cloud data using 'abfss://storage_account_details' .I ...
Hey @Mailendiran In Databricks, mounting storage to DBFS (Databricks File System) using the `abfss` protocol is a common practice for accessing data stored externally in Azure Blob Storage. While you typically use the full `abfss` path to access data...
Is there a way that I can set up and configure a Databricks workflow job and tasks from Databricks cli or api tools by using python? Any help would be appreciated. #databricksworkflow #databricks
Hello and yes, you can set up and configure a Databricks workflow job and tasks using Databricks CLI or API tools with Python. Here are some resources and steps to guide you:
Create and run Databricks Jobs: This document: ( https://docs.databrick...
Hi all!In our project, we're thinking about "Validation, Correction and Enrichment of Postal Addresses" with Databricks. For sure we'd need some kind of batch processing, because we have millions of addresses in our system.I'm aware of Address Valida...
Happy to help. Feel free to reach out https://www.linkedin.com/in/saleh-sultan-143ab036?utm_source=share&utm_campaign=share_via&utm_content=profile&utm_medium=android_app
Hi Team,Is there a particular reason why we should avoid using UDF and instead convert to DataFrame code?Are there any restrictions or limitations (in terms of performance or governance) when using UDFs in Databricks? Regards,Janga
Hello some of the things you need to take in consideration is that:UDFs might introduce significant processing bottlenecks into code execution. Databricks uses a number of different optimizers automatically for code written with included Apache Spark...