Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2022 03:02 PM
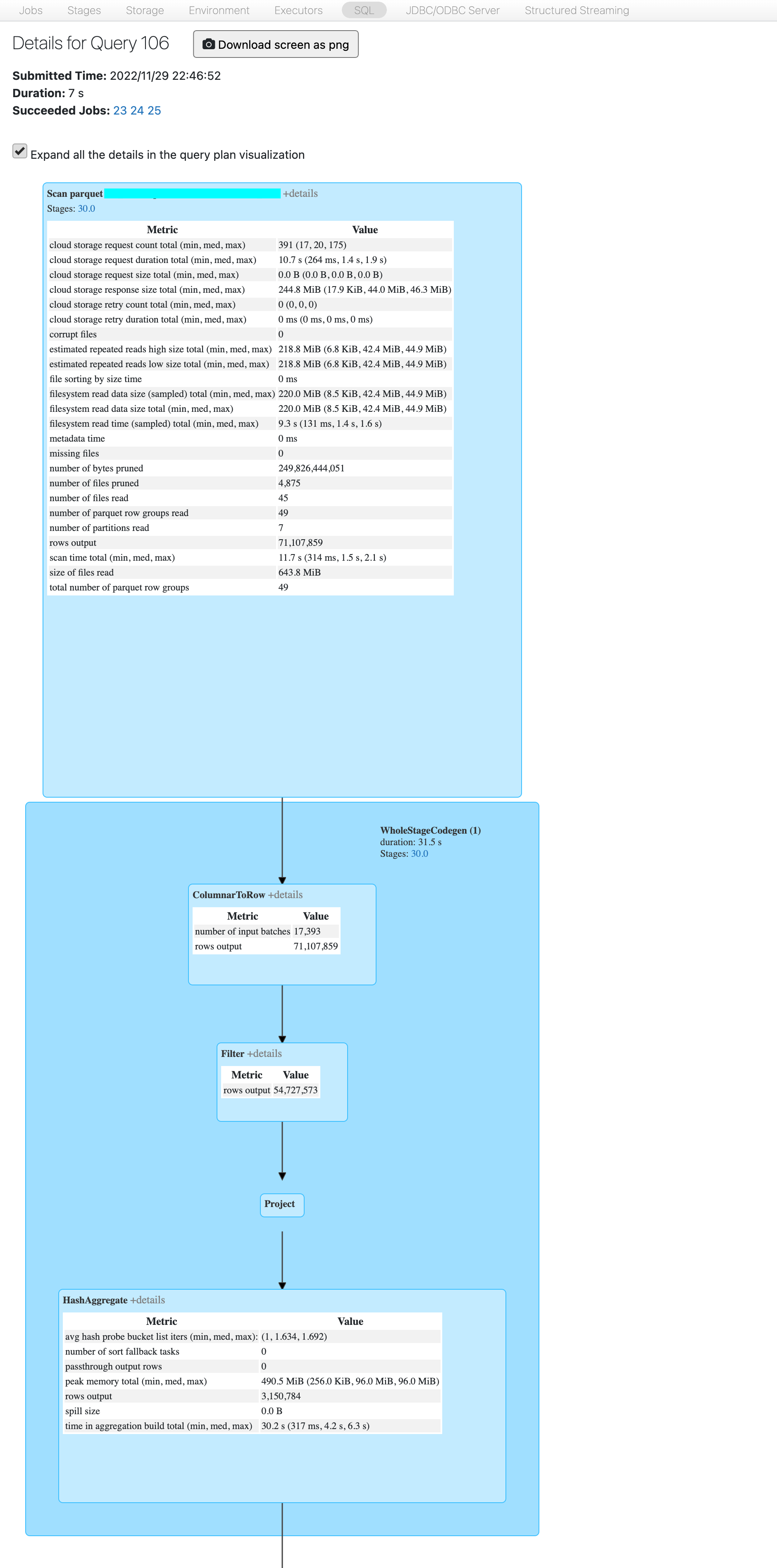
- I could not run your snippet because Scala is disallowed on the cluster, but DESC DETAIL shows 233 GiB in 4915 files. When launched without filter predicate, the biggest job shows input of size 105 GiB. Rows count: 23.5 B.
- The same cluster was used for the comparison, as comparing performance with a cluster of different size would be meaningless.
- Please validate the data below:


== Physical Plan ==
AdaptiveSparkPlan (22)
+- == Final Plan ==
* HashAggregate (13)
+- ShuffleQueryStage (12), Statistics(sizeInBytes=144.0 B, rowCount=9, isRuntime=true)
+- Exchange (11)
+- * HashAggregate (10)
+- * HashAggregate (9)
+- AQEShuffleRead (8)
+- ShuffleQueryStage (7), Statistics(sizeInBytes=161.2 MiB, rowCount=3.15E+6, isRuntime=true)
+- Exchange (6)
+- * HashAggregate (5)
+- * Project (4)
+- * Filter (3)
+- * ColumnarToRow (2)
+- Scan parquet ccc.sss.ttt (1)
+- == Initial Plan ==
HashAggregate (21)
+- Exchange (20)
+- HashAggregate (19)
+- HashAggregate (18)
+- Exchange (17)
+- HashAggregate (16)
+- Project (15)
+- Filter (14)
+- Scan parquet ccc.sss.ttt (1)
(1) Scan parquet ccc.sss.ttt
Output [4]: [Time#2824, TagName#2825, day#2831, isLate#2832]
Batched: true
Location: PreparedDeltaFileIndex [mcfs-abfss://t-125a3c9d-90a3-46dc-a577-196577aff13d+concon@sasasa.dfs.core.windows.net/tttddd/delta]
PushedFilters: [IsNotNull(Time), GreaterThanOrEqual(Time,2022-11-26 22:46:52.42), LessThanOrEqual(Time,2022-11-29 22:46:52.42)]
ReadSchema: struct<Time:timestamp,TagName:string>
(2) ColumnarToRow [codegen id : 1]
Input [4]: [Time#2824, TagName#2825, day#2831, isLate#2832]
(3) Filter [codegen id : 1]
Input [4]: [Time#2824, TagName#2825, day#2831, isLate#2832]
Condition : ((isnotnull(Time#2824) AND (Time#2824 >= 2022-11-26 22:46:52.42)) AND (Time#2824 <= 2022-11-29 22:46:52.42))
(4) Project [codegen id : 1]
Output [2]: [TagName#2825, date_trunc(minute, Time#2824, Some(Etc/UTC)) AS _groupingexpression#2839]
Input [4]: [Time#2824, TagName#2825, day#2831, isLate#2832]
(5) HashAggregate [codegen id : 1]
Input [2]: [TagName#2825, _groupingexpression#2839]
Keys [2]: [_groupingexpression#2839, TagName#2825]
Functions: []
Aggregate Attributes: []
Results [2]: [_groupingexpression#2839, TagName#2825]
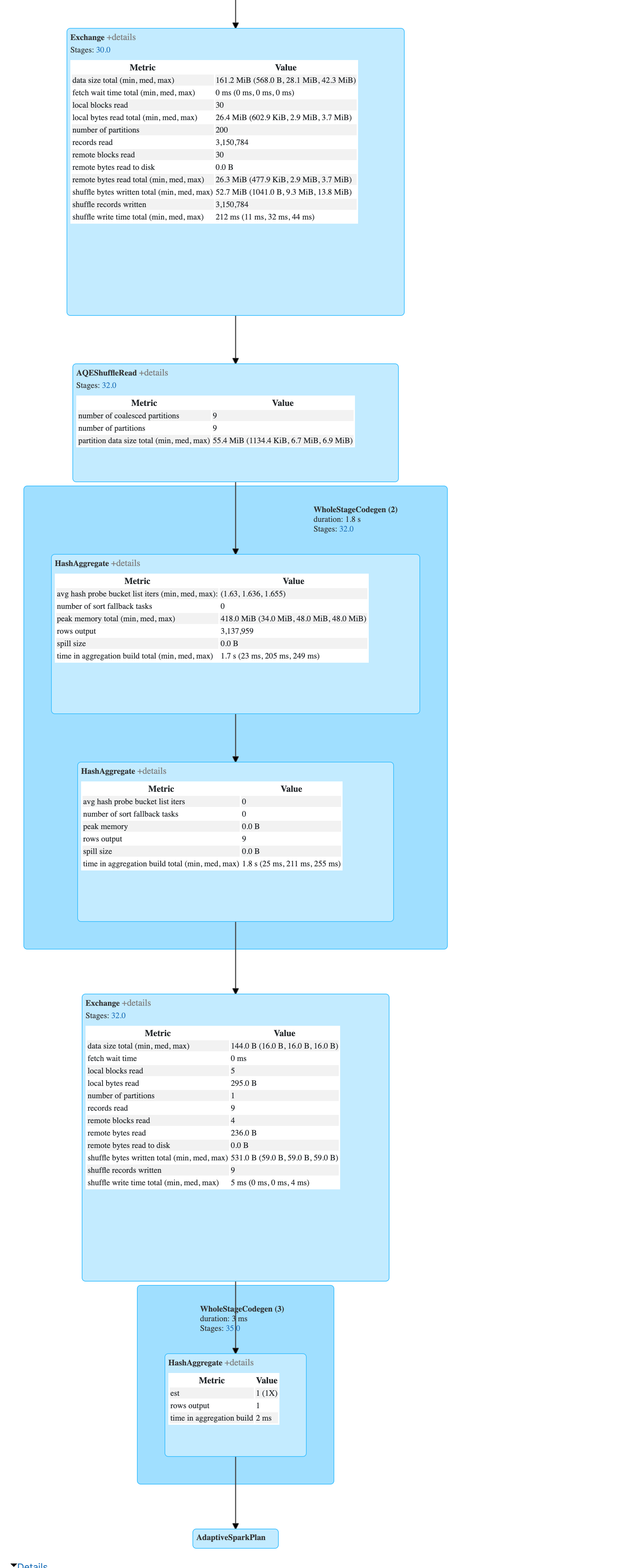
(6) Exchange
Input [2]: [_groupingexpression#2839, TagName#2825]
Arguments: hashpartitioning(_groupingexpression#2839, TagName#2825, 200), ENSURE_REQUIREMENTS, [id=#2040]
(7) ShuffleQueryStage
Output [2]: [_groupingexpression#2839, TagName#2825]
Arguments: 0, Statistics(sizeInBytes=161.2 MiB, rowCount=3.15E+6, isRuntime=true)
(8) AQEShuffleRead
Input [2]: [_groupingexpression#2839, TagName#2825]
Arguments: coalesced
(9) HashAggregate [codegen id : 2]
Input [2]: [_groupingexpression#2839, TagName#2825]
Keys [2]: [_groupingexpression#2839, TagName#2825]
Functions: []
Aggregate Attributes: []
Results: []
(10) HashAggregate [codegen id : 2]
Input: []
Keys: []
Functions [1]: [partial_count(1) AS count#2841L]
Aggregate Attributes [1]: [count#2840L]
Results [1]: [count#2841L]
(11) Exchange
Input [1]: [count#2841L]
Arguments: SinglePartition, ENSURE_REQUIREMENTS, [id=#2093]
(12) ShuffleQueryStage
Output [1]: [count#2841L]
Arguments: 1, Statistics(sizeInBytes=144.0 B, rowCount=9, isRuntime=true)
(13) HashAggregate [codegen id : 3]
Input [1]: [count#2841L]
Keys: []
Functions [1]: [finalmerge_count(merge count#2841L) AS count(1)#2833L]
Aggregate Attributes [1]: [count(1)#2833L]
Results [1]: [count(1)#2833L AS count(1)#2836L]
(14) Filter
Input [4]: [Time#2824, TagName#2825, day#2831, isLate#2832]
Condition : ((isnotnull(Time#2824) AND (Time#2824 >= 2022-11-26 22:46:52.42)) AND (Time#2824 <= 2022-11-29 22:46:52.42))
(15) Project
Output [2]: [TagName#2825, date_trunc(minute, Time#2824, Some(Etc/UTC)) AS _groupingexpression#2839]
Input [4]: [Time#2824, TagName#2825, day#2831, isLate#2832]
(16) HashAggregate
Input [2]: [TagName#2825, _groupingexpression#2839]
Keys [2]: [_groupingexpression#2839, TagName#2825]
Functions: []
Aggregate Attributes: []
Results [2]: [_groupingexpression#2839, TagName#2825]
(17) Exchange
Input [2]: [_groupingexpression#2839, TagName#2825]
Arguments: hashpartitioning(_groupingexpression#2839, TagName#2825, 200), ENSURE_REQUIREMENTS, [id=#1937]
(18) HashAggregate
Input [2]: [_groupingexpression#2839, TagName#2825]
Keys [2]: [_groupingexpression#2839, TagName#2825]
Functions: []
Aggregate Attributes: []
Results: []
(19) HashAggregate
Input: []
Keys: []
Functions [1]: [partial_count(1) AS count#2841L]
Aggregate Attributes [1]: [count#2840L]
Results [1]: [count#2841L]
(20) Exchange
Input [1]: [count#2841L]
Arguments: SinglePartition, ENSURE_REQUIREMENTS, [id=#1941]
(21) HashAggregate
Input [1]: [count#2841L]
Keys: []
Functions [1]: [finalmerge_count(merge count#2841L) AS count(1)#2833L]
Aggregate Attributes [1]: [count(1)#2833L]
Results [1]: [count(1)#2833L AS count(1)#2836L]
(22) AdaptiveSparkPlan
Output [1]: [count(1)#2836L]
Arguments: isFinalPlan=trueIs that what you are asking about? Please let me know if I can provide more information.

{kind=link}
{kind=link}