- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-08-2022 10:11 AM
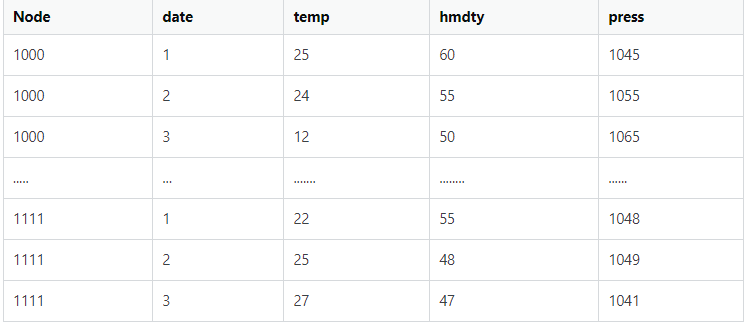
I have a large time series with many measuring stations recording the same 5 data (Temperature, Humidity, etc.) I want to predict a future moment with a time series model, for which I pass the data from all the measuring stations to the Deep Learning model. E.g. I have 100 days of recorded data, in which I have 1000 measuring stations, and each of them has 5 data. My spark table looks something like this:

How can I efficiently transpose my data using Spark and Pandas to something like this structure?

Sample code:
import pandas as pd
import random
import spark
data = []
for node in range(0,100):
for day in range(0,100):
data.append([str(node),
day,
random.randrange(15, 25, 1),
random.randrange(50, 100, 1),
random.randrange(1000, 1045, 1)])
df = spark.createDataFrame(data,['Node', 'day','Temp','hum','press'])
display(df)I don't process the data as a whole, but I use a period between two dates, say 10, 20, or 30 time instants.
A simple solution, like packing everything into memory... I can do it, but I don't know how to use it efficiently. My original dataset is a parquet of 8 columns and 6million rows (2000 NODE), so if I load it all into memory and transform it that way, I would get a 30,000 row (time) and 2000 * 8 columns table in memory.
So my question is how to load and transform such data effectively. I have parquet data on the disk and I load it to the machine with spark. I will pass the processed data to a Deep Learning model.
- Labels:
-
Dataframe
-
Deep learning

{kind=link}
{kind=link}