Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-15-2022 10:31 AM
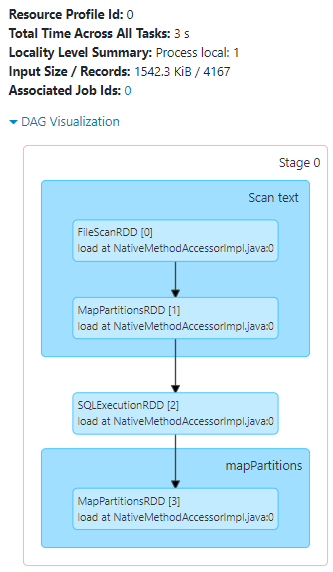
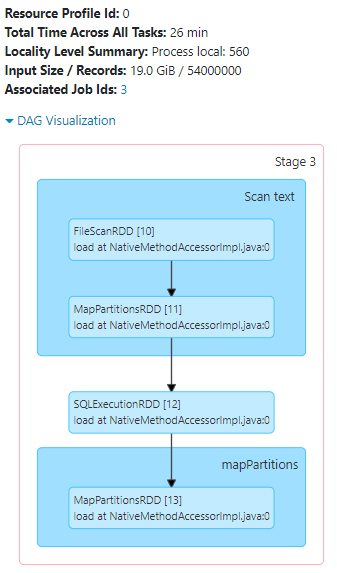
I created a test setup.
I generated lots of exemplary rows simulating log entries; for 90 days, each day with 600,000 log entries (=54,000,000 rows). Each entry has a log timestamp. I created another column for "binning" all entries in the nearest "5 minute" window.
I saved this data frame as JSON, partitioned by the 5min-timestamp column.
So I ended up with 12,960 folders containing each one JSON file.
Then I tried:
(
spark
.read
.format('json')
.load(f'{path_base_folder}/some_timestamp_bin_05m=2022-03-23 18%3A00%3A00')
.explain(extended=True)
)
As well as
(
spark
.read
.format('json')
.load(f'{path_base_folder}')
.filter( F.col('some_timestamp_bin_05m')=="2022-03-23 18:00:00")
.explain(extended=True)
)
Interestingly, prior to the read job, two more jobs are carried out; to scan the file system:


{kind=link}
{kind=link}
{kind=link}