Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-14-2022 02:52 AM
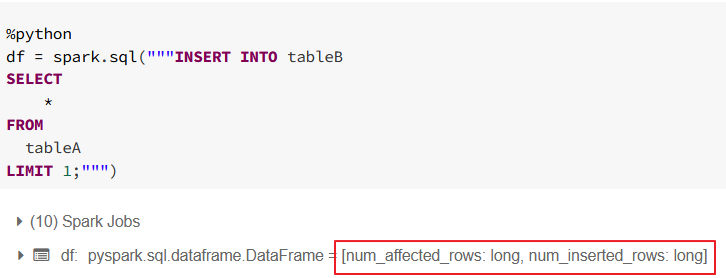
@@ROWCOUNT is rather T-SQL function not Spark SQL. I haven't found something like that in documentation but there is other way as every insert anyway return num_affected_rows and num_inserted_rows fields.
So you can for example use
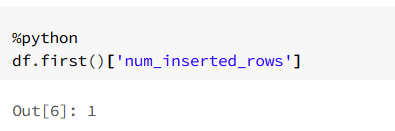
df.first()['num_inserted_rows'] or subquery and select in sql syntax.
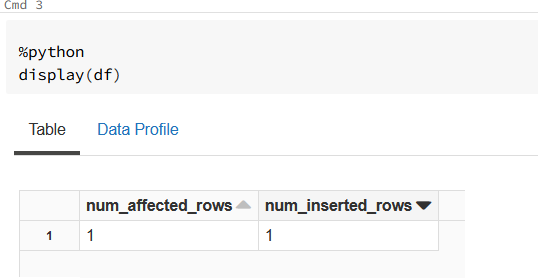
I am including example screenshots.



My blog: https://databrickster.medium.com/

{kind=link}
{kind=link}
{kind=link}