- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-09-2022 07:53 PM
@Vidula Khanna
@orian hindi
Today, I tried to transpose a big data set (Row: 252x17 Columns:1000). 999 columns are structured numerical float data and 1 column is a DateTime data type.
I deployed Standard_E4ds_v4 in Azure Databricks. That should be enough for transposing the big data.
Here is the code:
df_sp500_elements.pandas_api().set_index('stock_dateTime').T.reset_index().rename(columns={"index":"stock_dateTime"}).to_spark().show()However, after running for 14.45 hours, there is still a `Fatal error: The Python kernel is unresponsive`.
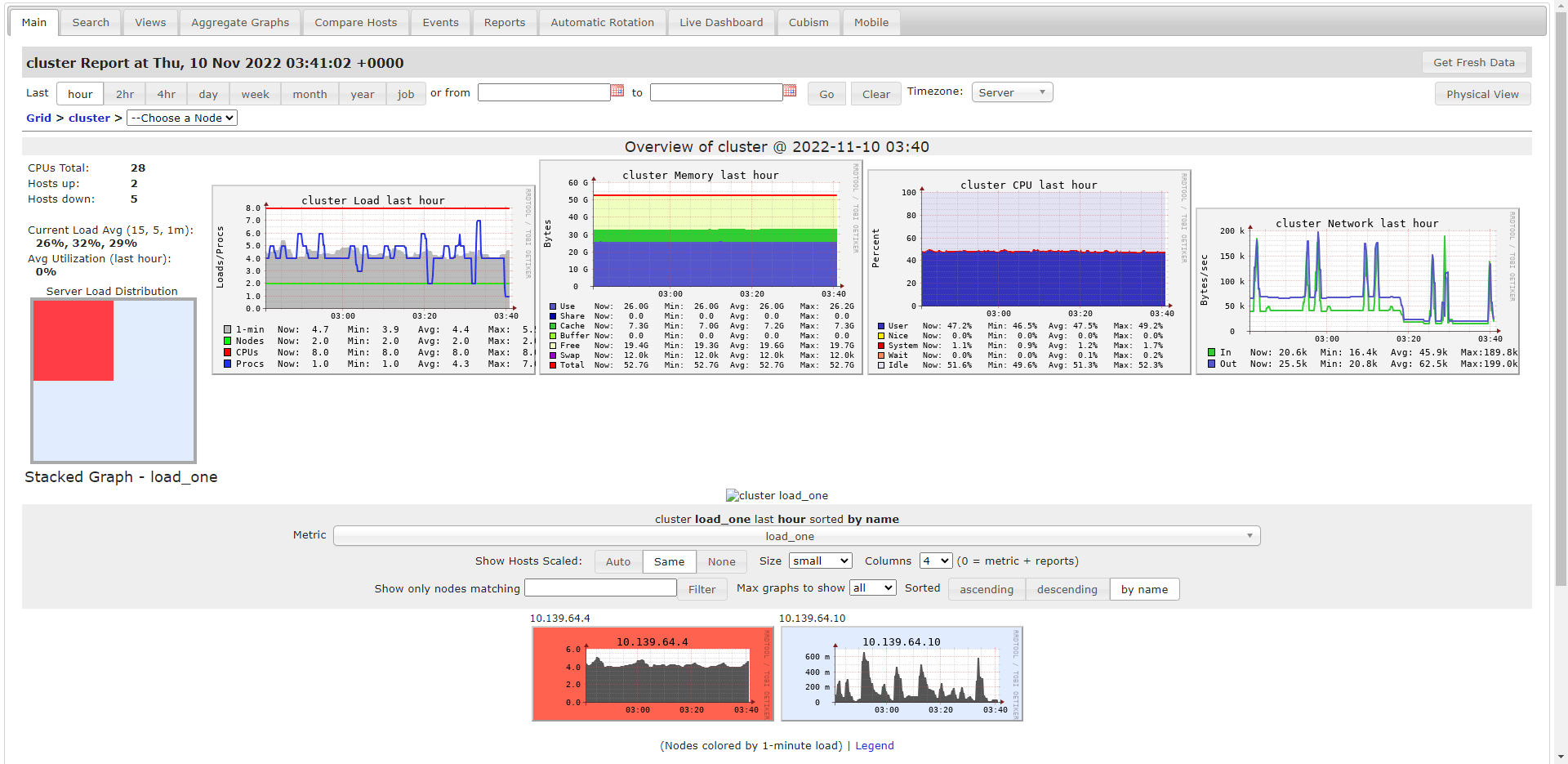
This is the Ganglia:: cluster Report during transposition ::

This is the Event log`:

I think the `Fatal error: The Python kernel is unresponsive` is not caused by insufficient RAM.
This is my full `Fatal error: The Python kernel is unresponsive.` error message:
---------------------------------------------------------------------------
The Python process exited with an unknown exit code.
The last 10 KB of the process's stderr and stdout can be found below. See driver logs for full logs.
---------------------------------------------------------------------------
Last messages on stderr:
Wed Nov 9 12:46:54 2022 Connection to spark from PID 933
Wed Nov 9 12:46:54 2022 Initialized gateway on port 34615
Wed Nov 9 12:46:55 2022 Connected to spark.
/databricks/spark/python/pyspark/sql/dataframe.py:3605: FutureWarning: DataFrame.to_pandas_on_spark is deprecated. Use DataFrame.pandas_api instead.
warnings.warn(
ERROR:root:KeyboardInterrupt while sending command.
Traceback (most recent call last):
File "/databricks/spark/python/pyspark/sql/pandas/conversion.py", line 364, in _collect_as_arrow
results = list(batch_stream)
File "/databricks/spark/python/pyspark/sql/pandas/serializers.py", line 56, in load_stream
for batch in self.serializer.load_stream(stream):
File "/databricks/spark/python/pyspark/sql/pandas/serializers.py", line 112, in load_stream
reader = pa.ipc.open_stream(stream)
File "/databricks/python/lib/python3.9/site-packages/pyarrow/ipc.py", line 154, in open_stream
- return RecordBatchStreamReader(source)

{kind=link}
{kind=link}