- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-08-2023 08:25 AM
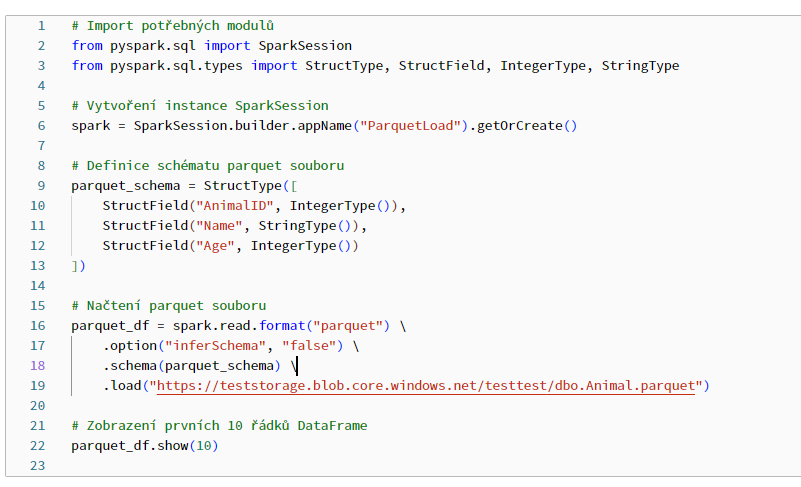
Sure, first error which popped up was (code from notebook below in screenshot):
AnalysisException: Incompatible format detected. A transaction log for Delta was found at `https://teststorage.blob.core.windows.net/testtest/dbo.Animal.parquet/_delta_log`, but you are trying to read from `https://teststorage.blob.core.windows.net/testtest/dbo.Animal.parquet` using format("parquet"). You must use 'format("delta")' when reading and writing to a delta table. To disable this check, SET spark.databricks.delta.formatCheck.enabled=false To learn more about Delta, see https://docs.microsoft.com/azure/databricks/delta/index
I tried to fix it like "delta_df = spark.read.format("parquet") --> delta_df = spark.read.format("delta")"
Its dropped:
File /databricks/spark/python/pyspark/instrumentation_utils.py:48, in _wrap_function.<locals>.wrapper(*args, **kwargs) 46 start = time.perf_counter() 47 try: ---> 48 res = func(*args, **kwargs) 49 logger.log_success( 50 module_name, class_name, function_name, time.perf_counter() - start, signature 51 )
But I am not sure I do it in right way. Trying to finish my project and I made it through copy data pipeline, but I want to change into autoloader and storage data in delta table.
Thanks in advance.

{kind=link}