High cost of storage when using structured streaming
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-08-2023 02:12 PM
Hi there,
I read data from Azure Event Hub and after manipulating with data I write the dataframe back to Event Hub (I use this connector for that):
#read data
df = (spark.readStream
.format("eventhubs")
.options(**ehConf)
.load()
)
#some data manipulation
#write data
ds = df \
.select("body", "partitionKey") \
.writeStream \
.format("eventhubs") \
.options(**output_ehConf) \
.option("checkpointLocation", "/checkpoin/eventhub-to-eventhub/savestate.txt") \
.trigger(processingTime='1 seconds') \
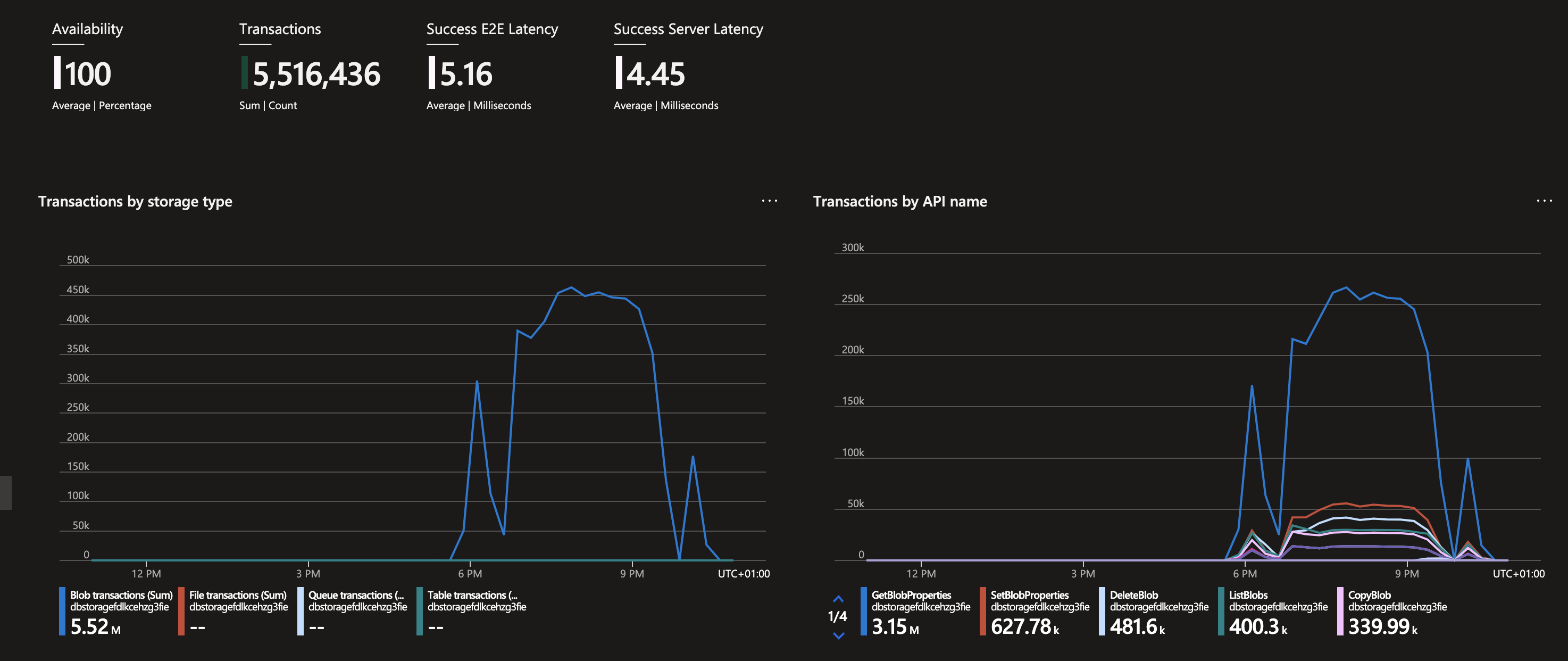
.start()In this case, I get high storage costs, which far exceed my computational costs (4 times). The expense is caused by a large number of transactions to the storage:

Question: am I using structured streaming correctly, and if so, how can I optimize storage costs?
Thank you for your time!
Labels:

{kind=link}