Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-28-2023 08:34 PM
Hi @Bruno Franco ,
Can you please try the below code, hope it might for you.
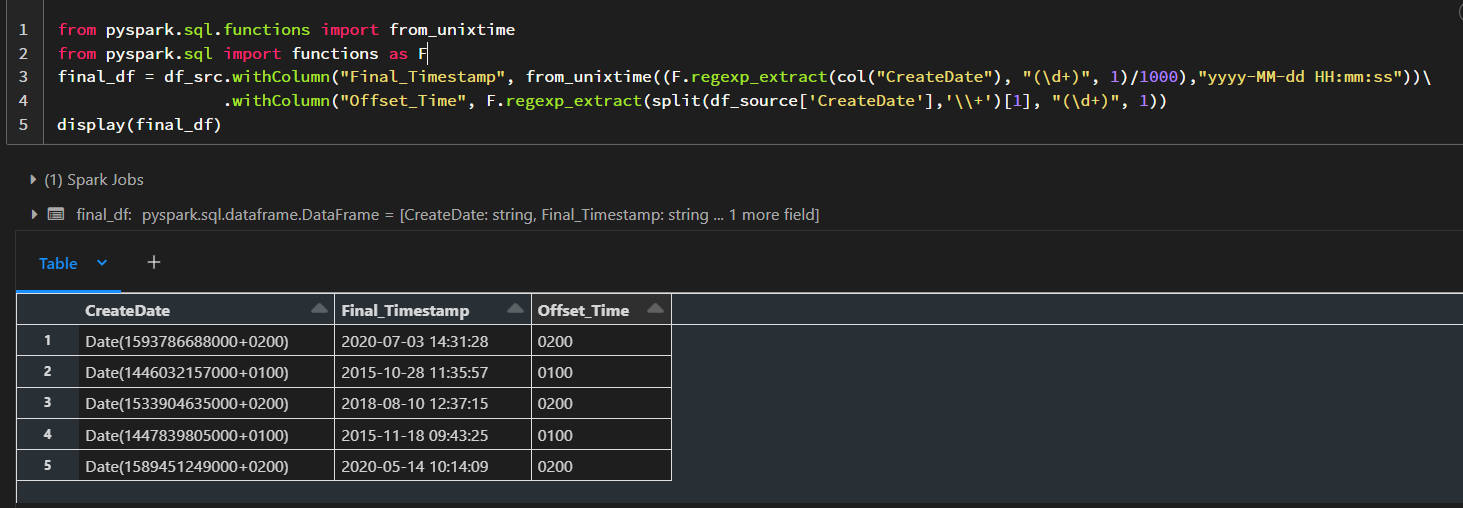
from pyspark.sql.functions import from_unixtime
from pyspark.sql import functions as F
final_df = df_src.withColumn("Final_Timestamp", from_unixtime((F.regexp_extract(col("CreateDate"), "(\d+)", 1)/1000),"yyyy-MM-dd HH:mm:ss"))\
.withColumn("Offset_Time", F.regexp_extract(split(df_source['CreateDate'],'\\+')[1], "(\d+)", 1))
display(final_df)
I have divided the value with 1000 because from_unixtime takes arguments in seconds, and your
timestamp is in milliseconds.
Happy Learning!!
Thanks for reading and like if this is useful and for improvements or feedback please comment.

{kind=link}