- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-12-2021 05:21 AM
Hello,
Took some more time investigating and trying @Sandeep Chandran idea.
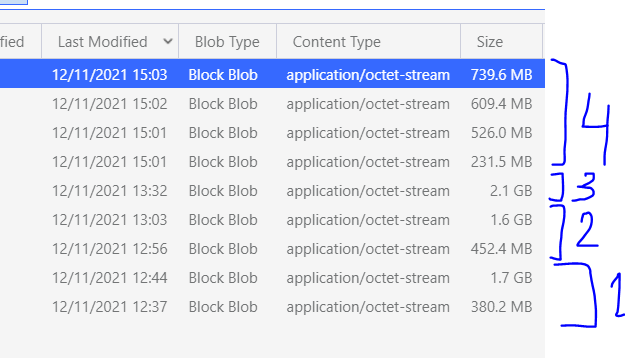
I ran 4 different configurations. I have cached the update table and each time I was running a restore on the target table so the data we merge are identical.
Here are the files produced by each run on my BIGGEST partition which is the one blocking the stage:

spark.databricks.delta.tuneFileSizesForRewrites: false
I suppose it uses file tuning on table size
run2:
spark.databricks.delta.tuneFileSizesForRewrites: false
spark.databricks.delta.optimize.maxFileSize: 268435456
run3:
spark.databricks.delta.tuneFileSizesForRewrites: false
delta.targetFileSize = 268435456 property on target table
run4:
spark.databricks.delta.tuneFileSizesForRewrites: true
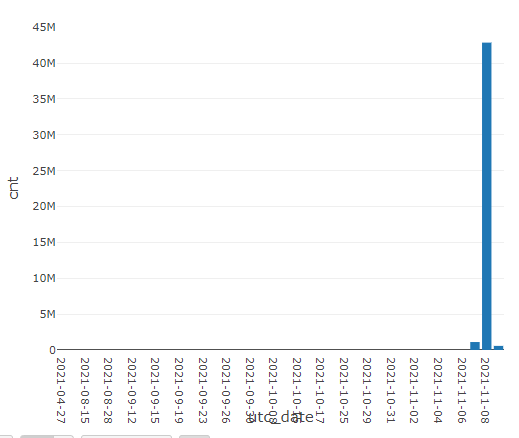
As an extra info here is the records per partition,. As you see my dataframe is highly unbalanced.


{kind=link}
{kind=link}