Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-13-2022 11:51 PM
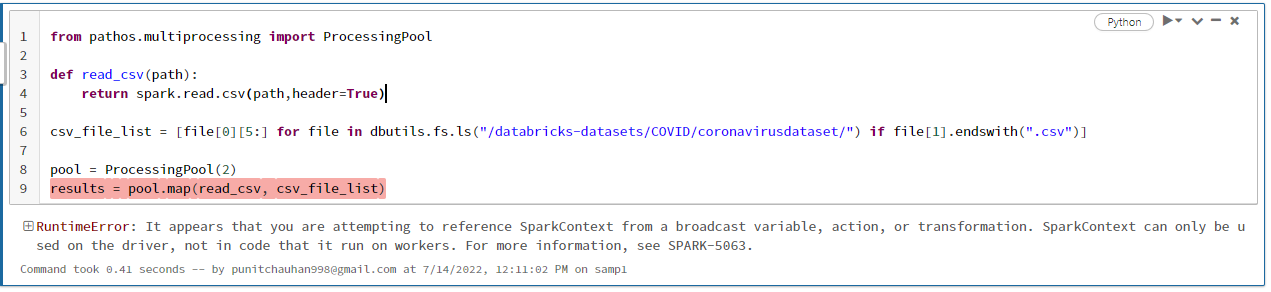
I'm using PySpark and Pathos to read numerous CSV files and create many DF, but I keep getting this problem.

from pathos.multiprocessing import ProcessingPool
def readCsv(path):
return spark.read.csv(path,header=True)
csv_file_list = [file[0][5:] for file in dbutils.fs.ls("/databricks-datasets/COVID/coronavirusdataset/") if file[1].endswith(".csv")]
pool = ProcessingPool(2)
results = pool.map(readCsv, csv_file_list)
Labels:
- Labels:
-
Multiple

{kind=link}