- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-10-2022 09:34 AM

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-11-2022 01:21 AM
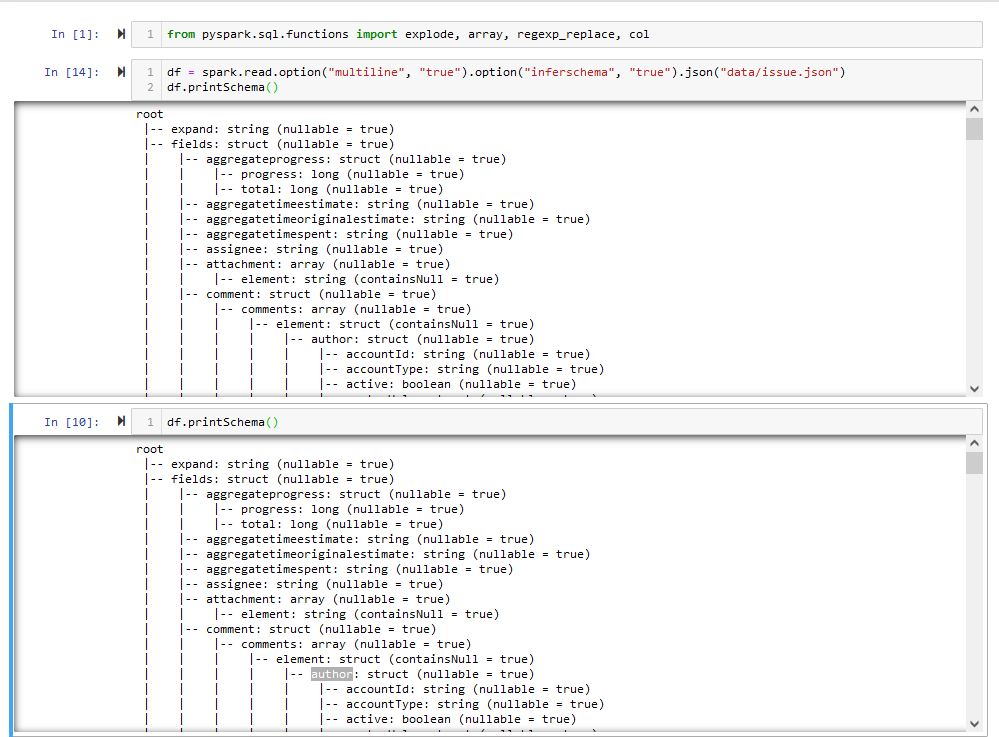
if columns are missing, that particular data is not present in the json. I am not aware of spark skipping columns when reading json with inferschema. There is an option dropFieldIfAllNull but that is False by default.
That makes me think: you might wanna look into the options of read.json
https://spark.apache.org/docs/latest/sql-data-sources-json.html
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-11-2022 04:19 AM
Now it's working, when the message returned that it was not parallelized I searched and found the answer. When creating the Dataframe I changed it to:
@Werner Stinckens Thanks for the support.
df = spark.read.json(sc.parallelize([answer.text]))
{kind=link}