I have tried multiples way to set row group for delta tables on data bricks notebook its not working where as I am able to set it properly using spark.I tried 1. val blockSize = 1024 * 1024 * 60spark.sparkContext.hadoopConfiguration.setInt( "dfs.bloc...
Hi @dlaxminaresh, Setting row groups for Delta tables in Databricks can be a bit tricky, but let’s explore some options to achieve this.
First, let’s address the approaches you’ve tried:
Setting Block Sizes:
You’ve attempted to set the block size...
I am trying to set up CI/CD with azure devops and 3 workspaces, dev, test, prod using asset bundlesAll 3 workspaces will have their own catalog in unity catalog. I can't find a way to change which catalog should be used by the jobs and dlt pipelines ...
Hi @JonathanFlint, Setting up CI/CD with Azure DevOps for Unity projects involving multiple workspaces and catalogs can be achieved.
Here are some approaches you can consider:
Catalog Switching at Runtime:
At the beginning of your program, issue ...
I understand only a limited spark configurations are supported in SQL Warehouse but is it possible to add spark extensions to SQL Warehouse clusters?Use Case: We've a few restricted table properties. We prevent that with spark extensions installed in...
Hi @naveenanto, While SQL Data Warehouse (now known as Azure Synapse Analytics) has some limitations when it comes to Spark configurations, you can indeed extend its capabilities by adding custom Spark extensions.
Let me provide you with some inform...
Hi there everyone,We are trying to get hands on Databricks Lakehouse for a prospective client's project.Our Major aim for the project is to Compare Datalakehosue on Databricks and Bigquery Datawarehouse in terms of Costs and time to setup and run que...
Hi @ashraf1395, Comparing Databricks Lakehouse and Google BigQuery is essential to make an informed decision for your project.
Let’s address your questions:
Cluster Configurations for Databricks:
Databricks provide flexibility in configuring com...
Hello, I am trying to download lists from SharePoint into a pandas dataframe. However I cannot get any information successfully. I have attempted many solution mentioned in stackoverflow. Below is one of those attempts: # https://pypi.org/project/sha...
The error "<urlopen error [Errno -2] Name or service not known>" suggests that there's an issue with the server URL or network connectivity. Double-check the server URL to ensure it's correct and accessible. Also, verify that your network connection ...
Hello, we're working with a serverless SQL cluster to query Delta tables and display some analytics in dashboards. We have some basic group by queries that generate around 36k lines, and they are executed without the "limit" key word. So in the data ...
Hey @RabahO
This is likely a memory issue.
The current behavior is that Databricks will only attempt to display the first 64000 rows of data. If the first 64000 rows of data are larger than 2187 MB, then it will fail to display anything. In your cas...
Hi All,I want to add a member to a group in databricks account level using rest api (https://docs.databricks.com/api/azure/account/accountgroups/patch) as mentioned in this link I could able to authenticate but not able to add member while using belo...
Hi @Kaniz I have tried suggest body also but still member is not added to group. is there any other method that i can use add member to the group at account levelThanks,Phani.
I've created a streaming live table from a foreign catalog. When I run the DLT pipeline it fils with "com.databricks.cdc.spark.DebeziumJDBCMicroBatchProvider not found".I haven't seen any documentation that suggests I need to install Debezium manuall...
Hi @smedegaard, The error message you’re encountering, “com.databricks.cdc.spark.DebeziumJDBCMicroBatchProvider not found,” indicates that the specified class is not available in your classpath.
To address this issue, follow these steps:
Verif...
Hi community,Currently, I am training models on databricks cluster and use mlflow to log and register models. My goal is to send notification to me when a new version of registered model happens (if the new run achieves some model performance baselin...
Hi @Chengzhu, It seems like you’re using MLflow’s Model Registry to manage the lifecycle of your machine learning models.
Let’s explore this further.
The MLflow Model Registry provides a centralized model store, APIs, and a UI to collaboratively m...
Hello - We're migrating from T-SQL to Spark SQL. We're migrating a significant number of queries."datediff(unit, start,end)" is different between these two implementations (in a good way). For the purpose of migration, we'd like to stay as consiste...
Hi @EWhitley, You’re on the right track with creating a custom UDF in Python for your migration.
To achieve similar behaviour to the T-SQL DATEDIFF function with an enum-like unit parameter, you can follow these steps:
Create a Custom UDF:
Define...
Hello all,I'm currently working on importing some SQL functions from Informix Database into Databricks using Asset Bundle deploying Delta Live Table to Unity Catalog. I'm struggling importing a recursive one, there is the code :CREATE FUNCTION "info...
Hi @YannLevavasseur, It looks like you’re dealing with a recursive SQL function for calculating the weight of articles in a Databricks environment. Handling recursion in SQL can be tricky, especially when translating existing Informix code to Data...
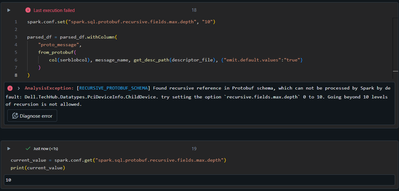
I am receiving protobuf data in a json attribute and along with it I receive a descriptor file.I am using from_protobuf to deserialize the data as below,It works most of the time but giving error when there are some recursive fields within the protob...
Hi @Sambit_S, Handling recursive fields in Protobuf can indeed be tricky, especially when deserializing data.
Let’s explore some potential solutions to address this issue:
Casting Issue with Recursive Fields: The error you’re encountering might b...
Hi, I'm implementing Databricks Asset bundles, my scripts are in GitHub and my /resource has all the .yml of my Databricks workflow which are pointing to the main branch git_source:
git_url: https://github.com/xxxx
git_provider: ...
Hi @Skr7 , Let’s break down your requirements:
Dynamically Changing Git Branch for Databricks Asset Bundles (DABs): When deploying and running your DAB, you want the Databricks workflows to point to your feature branch instead of the main branch....
Why can I use boto3 to go to secrets manager to retrieve a secret with a personal cluster but I get an error with a shared cluster?NoCredentialsError: Unable to locate credentials
Hi @dbdude and @drii_cavalcanti , The NoCredentialsError you’re encountering when using Boto3 to retrieve a secret from AWS Secrets Manager typically indicates that the AWS SDK is unable to find valid credentials for your API request.
Let’s explor...
Hi ,I have a Databricks job that results in a dashboard post run , I'm able to download the dashboard as HTML from the view job runs page , but I want to automate the process , so I tried using the Databricks API , but it says {"error_code":"INVALID_...
Hi @Skr7, You cannot automate exporting the dashboard as HTML using the Databricks API. The Databricks API only supports exporting results for notebook task runs, not for job run dashboards.
Here's the relevant excerpt from the provided sources:
Exp...