- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-30-2016 01:28 PM
I'm relatively new to Scala. In the past, I was able to do the following python:
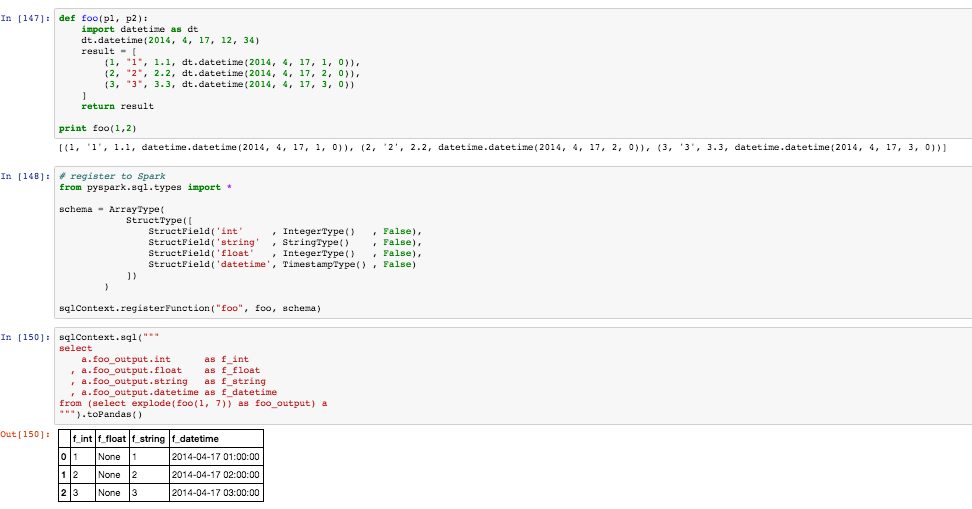
def foo(p1, p2):
import datetime as dt
dt.datetime(2014, 4, 17, 12, 34)
result = [
(1, "1", 1.1, dt.datetime(2014, 4, 17, 1, 0)),
(2, "2", 2.2, dt.datetime(2014, 4, 17, 2, 0)),
(3, "3", 3.3, dt.datetime(2014, 4, 17, 3, 0))
]
return resultNow I register it to a UDF:
from pyspark.sql.types import *
schema = ArrayType(
StructType([
StructField('int' , IntegerType() , False),
StructField('string' , StringType() , False),
StructField('float' , IntegerType() , False),
StructField('datetime', TimestampType() , False)
])
)
sqlContext.registerFunction("foo", foo, schema)
Finally, here is how I intend to use it:
sqlContext.sql("""
select
a.foo_output.int as f_int
, a.foo_output.float as f_float
, a.foo_output.string as f_string
, a.foo_output.datetime as f_datetime
from (select explode(foo(1, 7)) as foo_output) a
""").show()
This actual works in pyspark as shown above. See

I was not able to get the same thing to work in scala. Can anyone point me to the proper way to do this in scala/spark. When I tried to register the schema:
def foo(p1 :Integer, p2 :Integer)
: Array[Tuple4[Int, String, Float, Timestamp]] =
{
val result = Array(
(1, "1", 1.1f, new Timestamp(2014, 4, 17, 1, 0, 0, 0)),
(2, "2", 2.2f, new Timestamp(2014, 4, 17, 2, 0, 0, 0)),
(3, "3", 3.3f, new Timestamp(2014, 4, 17, 3, 0, 0, 0))
);
return result;
}
// register to Spark
val foo_schema = ArrayType(StructType(Array(
StructField("int" , IntegerType , false),
StructField("string" , StringType , false),
StructField("float" , FloatType , false),
StructField("datetime", TimestampType, false)
))
);
sql_context.udf.register("foo", foo _); I get a runtime error:
org.apache.spark.sql.AnalysisException: No such struct field int in _1, _2, _3, _4; line 2 pos 4
So, from the error message, it seems obvious that I didn't attach the schema properly and indeed in the above code, nowhere did I tell spark about it. So I tried to the following:
sql_context.udf.register("foo", foo _, foo_schema);
However, it gives me a compiler error:
[ERROR] /Users/rykelley/Development/rovi/IntegralReach-Main/ADW/rovi-master-schedule/src/main/scala/com/rovicorp/adw/RoviMasterSchedule/BuildRoviMasterSchedule.scala:247: error: overloaded method value register with alternatives:
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF22[_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF21[_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF20[_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF19[_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF18[_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF17[_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF16[_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF15[_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF14[_, _, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF13[_, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF12[_, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF11[_, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF10[_, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF9[_, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF8[_, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF7[_, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF6[_, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF5[_, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF4[_, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF3[_, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF2[_, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF1[_, _],returnType: org.apache.spark.sql.types.DataType)Unit
[INFO] cannot be applied to (String, (Integer, Integer) => Array[(Int, String, Float, java.sql.Timestamp)], org.apache.spark.sql.types.ArrayType)
Can someone point me in the right direction?
Note: using spark 1.6.1.
Thanks
Ryan

{kind=link}