- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-02-2022 02:08 AM
I have a notebook functioning as a pipeline, where multiple notebooks are chained together.
The issue I'm facing is that some of the notebooks are spark-optimized, others aren't, and what I want is to use 1 cluster for the former and another for the latter. However, this would mean changing clusters halfway through the pipeline notebook. Is that possible? And if so, how?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-02-2022 02:11 AM
In such a case, orchestrating those jobs using Azure Data Factory is highly recommended.
My blog: https://databrickster.medium.com/
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-02-2022 02:13 PM
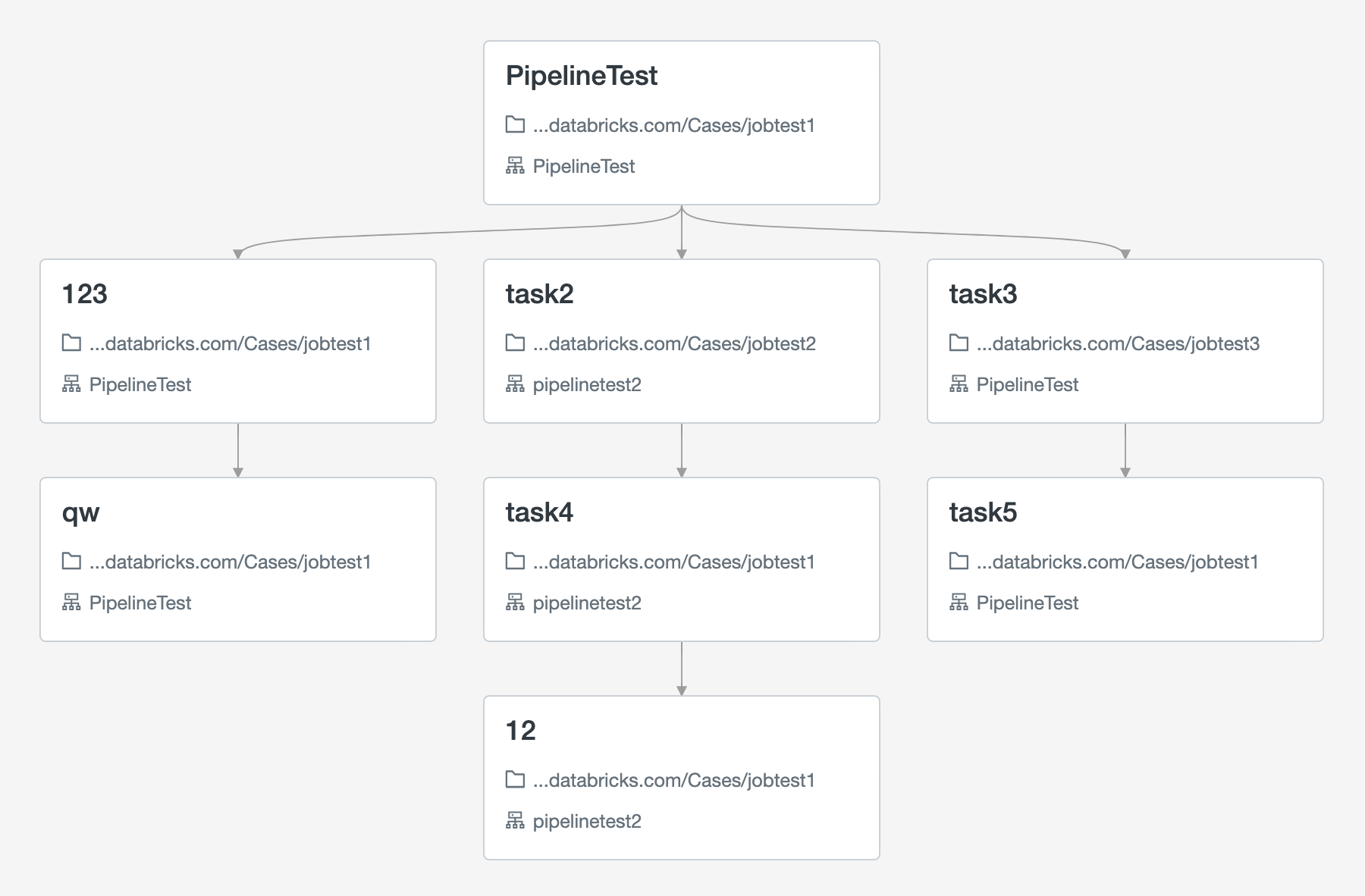
Yes, you can achieve this by setting two different job clusters. In the screenshot, you can see I have used 2 job clusters PipelineTest and pipelinetest2. You can refer the doc https://docs.databricks.com/jobs.html#cluster-config-tips

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-26-2022 01:28 AM
Hi Kaniz, sorry for the incredibly late reply. My notifications for responses ended up in my spam folder!
I ended up using ADF, but tried @Prabakar Ammeappin 's solution and that worked too!

{kind=link}