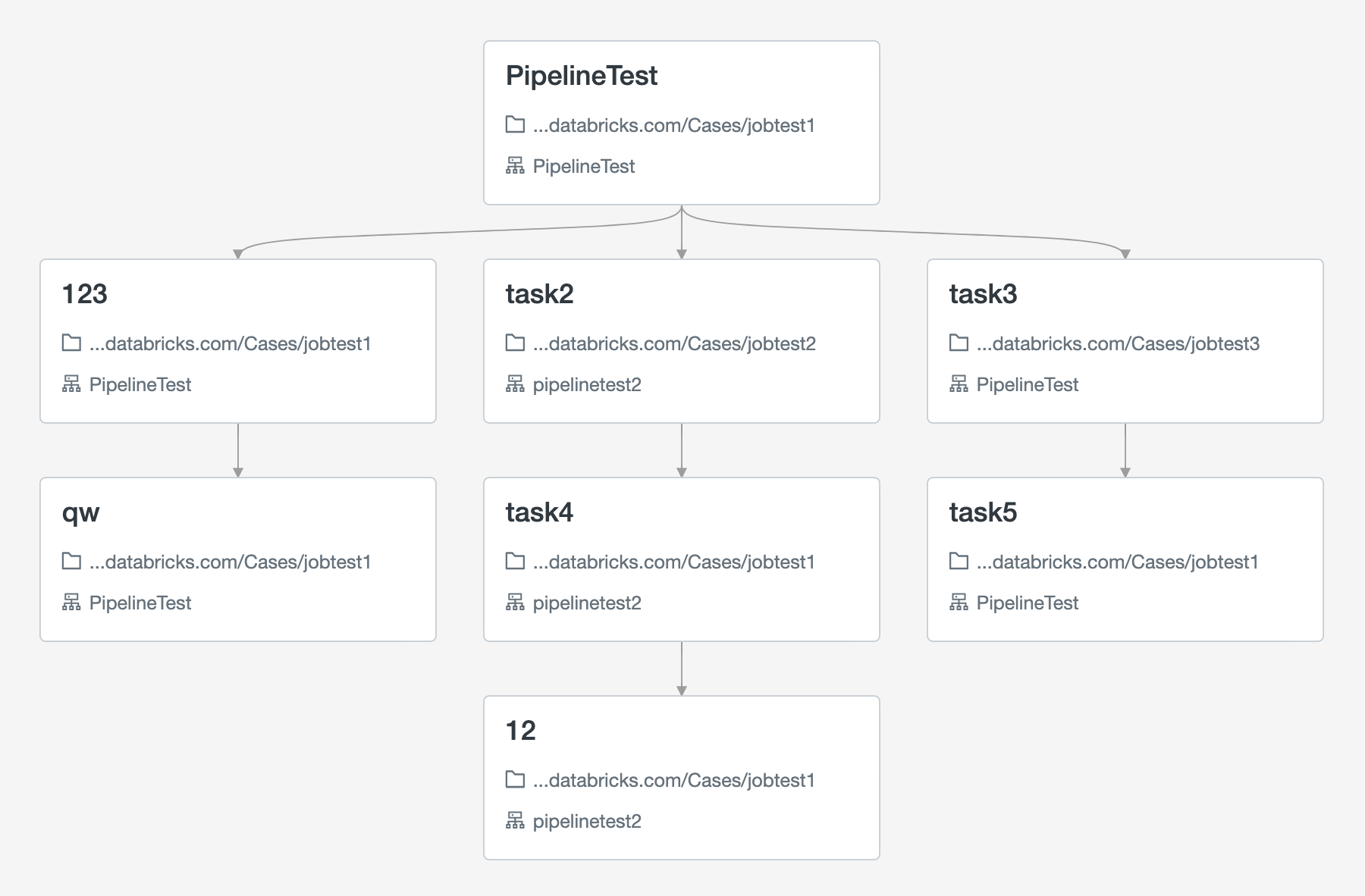
I have a notebook functioning as a pipeline, where multiple notebooks are chained together.
The issue I'm facing is that some of the notebooks are spark-optimized, others aren't, and what I want is to use 1 cluster for the former and another for the latter. However, this would mean changing clusters halfway through the pipeline notebook. Is that possible? And if so, how?








{kind=link}