Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Can't write / overwrite delta table with error: ox...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-15-2023 03:09 AM
Current Cluster Config:
Standard_DS3_v2 (14GB, 4 Cores) 2-6 workers
Standard_DS3_v2 (14GB, 4Cores) for driver
Runtime: 10.4x-scala2.12
We want to overwrite a temporary delta table with new records. The records will be load by another delta table and transformed in a notebook. This records have a column with a large string value.
We think the error occours because the driver have to handle to many memory. So we tested different configurations with the cluster (e.g. spark.executor.memory, spark.driver.memory, ...)
We also tested repartitioning and maxRowsInMemory. Sometimes our job runs, but at the most time we get such errors.
e.g.
Notebook-Error:
o1161.saveAsTable, o1158.saveAsTable, ...
193
194 print(f"Overwrites records in delta table '{full_table_name}'.")
--> 195 df.write.format("delta")\
196 .partitionBy("Year", "TypeOfTapChanger") \
197 .mode("overwrite") \
/databricks/spark/python/pyspark/sql/readwriter.py in saveAsTable(self, name, format, mode, partitionBy, **options)
804 if format is not None:
805 self.format(format)
--> 806 self._jwrite.saveAsTable(name)
807
808 def json(self, path, mode=None, compression=None, dateFormat=None, timestampFormat=None,
/databricks/spark/python/lib/py4j-0.10.9.1-src.zip/py4j/java_gateway.py in __call__(self, *args)
1302
1303 answer = self.gateway_client.send_command(command)
-> 1304 return_value = get_return_value(
1305 answer, self.gateway_client, self.target_id, self.name)
1306
/databricks/spark/python/pyspark/sql/utils.py in deco(*a, **kw)
115 def deco(*a, **kw):
116 try:
--> 117 return f(*a, **kw)
118 except py4j.protocol.Py4JJavaError as e:
119 converted = convert_exception(e.java_exception)
/databricks/spark/python/lib/py4j-0.10.9.1-src.zip/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name)
324 value = OUTPUT_CONVERTER[type](answer[2:], gateway_client)
325 if answer[1] == REFERENCE_TYPE:
--> 326 raise Py4JJavaError(
327 "An error occurred while calling {0}{1}{2}.\n".
328 format(target_id, ".", name), value)
Py4JJavaError: An error occurred while calling o1161.saveAsTable.
: org.apache.spark.SparkException: Job aborted.
...
...
Driver-Error:
23/02/15 10:58:38 INFO Executor: Finished task 2.0 in stage 139.0 (TID 926). 2578 bytes result sent to driver
23/02/15 10:58:38 INFO CoarseGrainedExecutorBackend: Got assigned task 955
23/02/15 10:58:38 INFO TorrentBroadcast: Started reading broadcast variable 144 with 1 pieces (estimated total size 4.0 MiB)
23/02/15 10:58:39 INFO MemoryStore: Block broadcast_144_piece0 stored as bytes in memory (estimated size 42.8 KiB, free 3.0 GiB)
23/02/15 10:58:39 INFO TorrentBroadcast: Reading broadcast variable 144 took 1077 ms
23/02/15 10:58:39 INFO MemoryStore: Block broadcast_144 stored as values in memory (estimated size 149.3 KiB, free 3.0 GiB)
23/02/15 10:58:39 INFO Executor: Running task 7.0 in stage 140.0 (TID 955)
23/02/15 10:58:39 INFO CodeGenerator: Code generated in 200.255017 ms
23/02/15 10:58:40 INFO TorrentBroadcast: Started reading broadcast variable 141 with 1 pieces (estimated total size 4.0 MiB)
23/02/15 10:58:41 INFO CodeGenerator: Code generated in 1729.166417 ms
23/02/15 10:58:46 ERROR Utils: Uncaught exception in thread stdout writer for /databricks/python/bin/python
java.lang.OutOfMemoryError: Java heap space
at org.apache.spark.sql.execution.python.PythonUDFRunner$$anon$2.read(PythonUDFRunner.scala:78)
at org.apache.spark.sql.execution.python.PythonUDFRunner$$anon$2.read(PythonUDFRunner.scala:68)
...
...
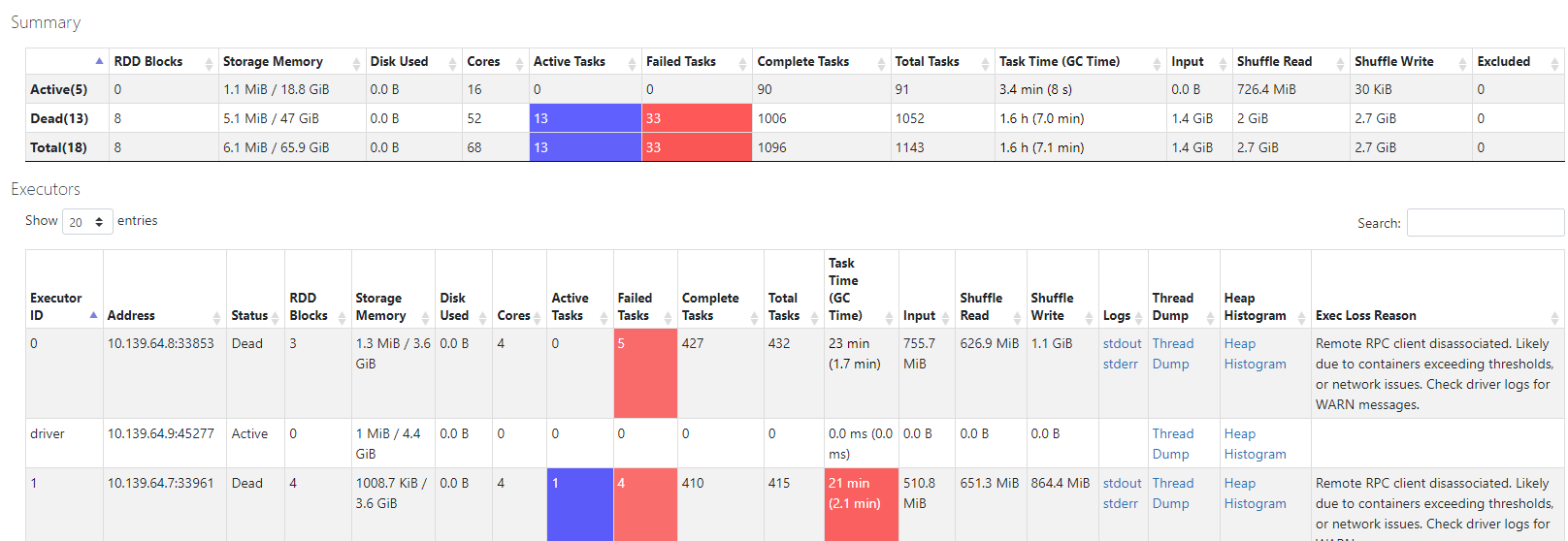
Executors in UI:


We hope you can help us, to understand and fix this problem.
Labels:
- Labels:
-
Delta table
-
Driver Error
-
Error
-
Standard
-
Table
1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-22-2023 05:32 AM
Hi @Tom Wein , you can check this link for pandas udf: https://www.databricks.com/blog/2020/05/20/new-pandas-udfs-and-python-type-hints-in-the-upcoming-rel...
If you cannot convert the python udf to pandas udf, you can also set the configuration: spark.conf.set("spark.databricks.execution.pythonUDF.arrow.enabled", True)
9 REPLIES 9
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-15-2023 04:06 AM
Hi @Tom Wein ,
What is your data size which you are trying to write?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-15-2023 04:38 AM
Hi, we use currently 250 files in one notebook, with approximately 8MB per file. (But normally we want to run 500.000 files)
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-16-2023 06:43 AM
Hi @Tom Wein , I see the error message is pointing to Python UDF(PythonUDFRunner.scala). The problem with Python UDF is the execution takes place on driver. This is putting pressure on Driver. The best way would be to be able to achieve the UDF functionality without the need of UDF. However, if that is not feasible then we have couple of options:
- Switch to Pandas UDF or configure arrow optimisation by setting spark.conf.set("spark.databricks.execution.pythonUDF.arrow.enabled", True)
- Use a bigger instance for Driver
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-17-2023 12:01 AM
Thank you for your answer. I will test it and give you a feedback.
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-21-2023 09:28 PM
Hi @Tom Wein
Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help.
We'd love to hear from you.
Thanks!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-21-2023 11:24 PM
Hi,
1. we changed our large string column to an array column
2. we use a bigger instance for the driver
So we can handle 500 files in our notebook transformation.
This runs the most time, but sporadically the same error occurs.
I could't change our UDF to pandas_udf. I do not really understand how to change it to an panas_udf.
Maybe you could help me, i would e.g. change this udf to a pandas_udf:
(Here we decode a binary content to a string content)
def decode_content(self, input_df: DataFrame) -> DataFrame:
print("Decode binary content to string")
# udf
def decode_content(s):
gzip = base64.b64decode(s)
gzip1 = gzip[4:]
return decompress(gzip1).decode()
# create udf
decode_content_udf = udf(lambda z: decode_content(z), StringType())
# use udf
result = input_df.withColumn("decoded", decode_content_udf(input_df.content))
result = result.select(col("decoded"))
return result
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-22-2023 05:32 AM
Hi @Tom Wein , you can check this link for pandas udf: https://www.databricks.com/blog/2020/05/20/new-pandas-udfs-and-python-type-hints-in-the-upcoming-rel...
If you cannot convert the python udf to pandas udf, you can also set the configuration: spark.conf.set("spark.databricks.execution.pythonUDF.arrow.enabled", True)
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-26-2023 11:39 PM
Hi,
thank you for your help!
We tested the configuration settings and it runs without any errors.
Could you give us some more information, where we can find some documentation about such settings. We searched hours to fix our problem. So we contacted this community. At the moment it is hard to find the correct documentaions to refine our code.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-27-2023 11:27 AM
Hi @Tom Wein , Good to know the suggestion helped!
I don't have exactly the document that provides this configuration. But the document I mentioned previously talks about Apache Arrow. So, we usually suggest using pandas udf as they already have arrow enabled. But if you can't use pandas udf, we can use the configuration to enable the same.
Announcements





{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Databricks OutOfMemory error on code that previously worked without issue in Data Engineering
- Hard reset programatically in Administration & Architecture
- Selective Overwrite to a Unity Catalog Table in Data Engineering
- How to enable CDF when saveAsTable from pyspark code? in Data Engineering
- what config do we use to set row groups fro delta tables on data bricks. in Data Engineering