Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Error while trying to implement Change Data Captur...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Error while trying to implement Change Data Capture
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-08-2023 05:41 PM
Hi All,
I'm new to databricks and learning towards taking up Associate Engineer Certification.
While going through the section "Build Data Pipelines with Delta Live Tables".
I'm trying to implement Change Data Capture, but it is erroring out when executing the workflow.
'm not sure if my code is incorrect as It is similar to what we have in the course material. Please see details below and kindly let me know how to fix this.
Screenshot of the Notebook used in the definition of the Pipeline.
Scroll down for the Code text and Error Text.

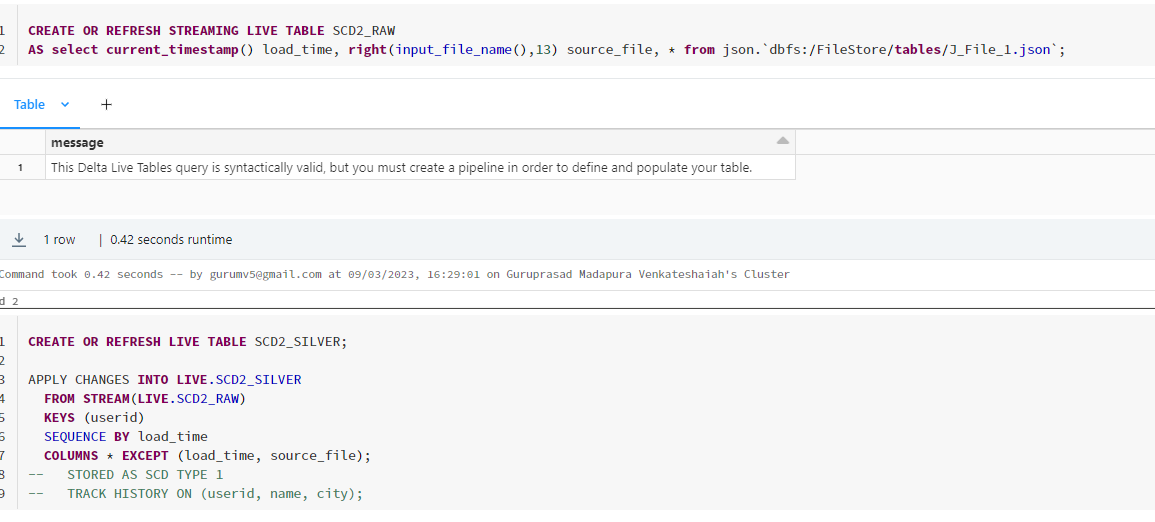
Code
CREATE OR REFRESH STREAMING LIVE TABLE SCD2_RAW
AS select current_timestamp() load_time, right(input_file_name(),13) source_file, * from json.`dbfs:/FileStore/tables/J_File_1.json`;
CREATE OR REFRESH STREAMING LIVE TABLE SCD2_SILVER;
APPLY CHANGES INTO LIVE.SCD2_SILVER
FROM STREAM(LIVE.SCD2_RAW)
KEYS (userid)
SEQUENCE BY load_time
COLUMNS * EXCEPT (load_time, source_file);
-- STORED AS SCD TYPE 1
-- TRACK HISTORY ON (userid, name, city);
Error
org.apache.spark.sql.AnalysisException: 'SCD2_RAW' is a streaming table, but 'SCD2_RAW' was not read as a stream. Either remove the STREAMING keyword after the CREATE clause or read the input as a stream rather than a table.
Thanks
Labels:
4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-09-2023 07:11 AM
Having had a quick look, I think your error is because you are trying to add SCD to a STREAMING LIVE table. I believe APPLY CHANGES INTO cannot be used on a streaming table.
You can use a streaming table as a source though.
Simply changing this line:
CREATE OR REFRESH STREAMING LIVE TABLE SCD2_SILVER;to:
CREATE OR REFRESH LIVE TABLE SCD2_SILVER;should be sufficient.
Do make sure you are running a compatible version of databricks. Also, if you want to use Track History, you need to set the pipeline cluster config:
pipelines.enableTrackHistoryto true.
I've also found the databricks SQL parser to give syntax errors sometimes and a little experimenting with removing line breaks, etc. can sometimes help track down errors.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-09-2023 05:01 PM
Thank you Kearon for taking time to answer.
I tried implementing the change suggested but seeing a different error now.
Error :
org.apache.spark.sql.AnalysisException: Unsupported SQL statement for table 'SCD2_SILVER': Missing query is not supported.
Modified Code:
CREATE OR REFRESH STREAMING LIVE TABLE SCD2_RAW
AS select current_timestamp() load_time, right(input_file_name(),13) source_file, * from json.`dbfs:/FileStore/tables/J_File_1.json`;
CREATE OR REFRESH LIVE TABLE SCD2_SILVER;
APPLY CHANGES INTO LIVE.SCD2_SILVER
FROM STREAM(LIVE.SCD2_RAW)
KEYS (userid)
SEQUENCE BY load_time
COLUMNS * EXCEPT (load_time, source_file);

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-10-2023 01:17 AM
@GURUPRASAD MADAPURA VENKATESHAIAH, I've had that error before. Trying to remember the cause....
I'll try to remember. In the mean time, here is a notebook I have that is very similar and works for me. If you try building yours up, step by step, using this as a template, hopefully that will do it. Obviously, you don't need the json explosion parts or the where clause. That's just to handle some messiness in the data I am processing.
CREATE OR REFRESH STREAMING LIVE TABLE currStudents_ingest
AS SELECT
col.*
,file_modification_time
FROM (
SELECT fi.file_modification_time, EXPLODE_OUTER (fi.students)
FROM STREAM(LIVE.currStudents_streamFiles) AS fi
)
WHERE col.id IS NOT NULL
;
CREATE OR REFRESH STREAMING LIVE TABLE currStudents_SCD;
APPLY CHANGES INTO
live.currStudents_SCD
FROM
stream(live.currStudents_ingest)
KEYS
(id)
SEQUENCE BY
file_modification_time
STORED AS
SCD TYPE 2
TRACK HISTORY ON * EXCEPT (file_modification_time)
;Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-20-2023 05:01 AM
Hi @GURUPRASAD MADAPURA VENKATESHAIAH(Customer), We haven't heard from you since the last response from @Kearon McNicol(Customer) , and I was checking back to see if his suggestions helped you.
Or else, If you have any solution, please share it with the community, as it can be helpful to others.
Also, Please don't forget to click on the "Select As Best" button whenever the information provided helps resolve your question.
Announcements





{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- How to Capture Change Data (CDC) from DynamoDB Streams and Write into Delta table of DataBricks in Data Engineering
- Fatal error when writing a big pandas dF in Data Engineering
- DLT SCD type 2 in bronze, silver and gold? Is it possible? in Data Engineering
- synapse pyspark delta lake merge scd type2 without primary key in Data Engineering
- Extra underscore behind ".xlsm" and ".xlsx" after exporting excel files from Databricks in Data Engineering