Hi all,
I'm preparing for the Databricks Data Engineer Associate exam and came across this question:
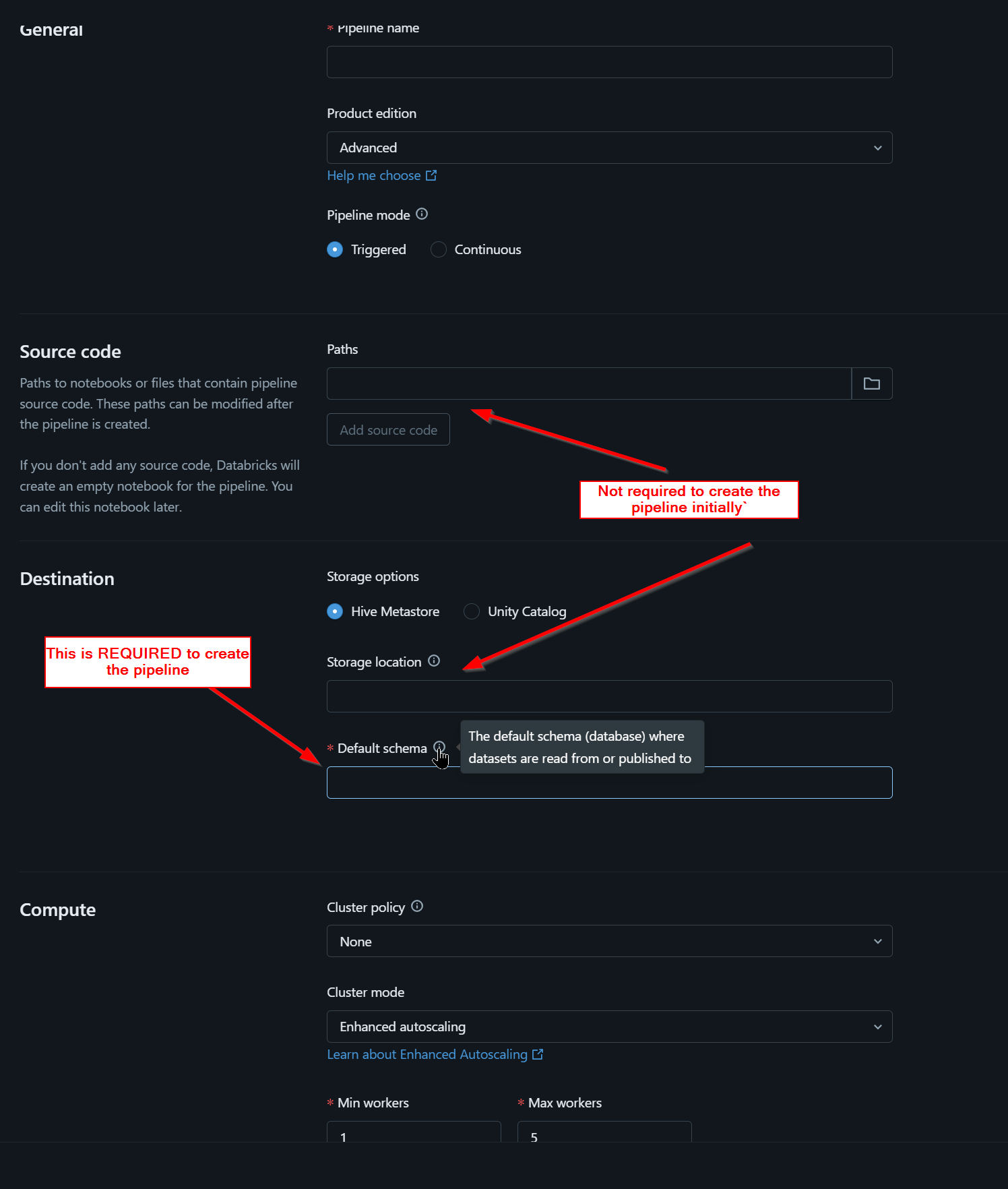
Which of the following must be specified when creating a new Delta Live Tables pipeline?
A. A key-value pair configuration
B. At least one notebook library to be executed
C. A path to cloud storage location for the written data
D. A location of a target database for the written data
From what I understand, some options like cloud storage paths and database names may be optional or inferred. I’d appreciate any clarification from the community or Databricks team on which of these is truly mandatory during pipeline creation.
Thanks in advance!







{kind=link}