Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Best way of loading several csv files in a table
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-17-2022 12:24 PM
What would be the best way of loading several files like in a single table to be consumed?
Labels:
- Labels:
-
Https


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-31-2022 05:36 AM
Yes,
1) Downloaded the files using sh from here https://s3.amazonaws.com/nyc-tlc/trip+data/yellow_tripdata_<year>-<month>.csv to /mnt
2) Loaded a dataframe with the csv files
3) Stored as a partitioned table
I don´t know if this the best approach, but its working
5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-18-2022 12:49 PM
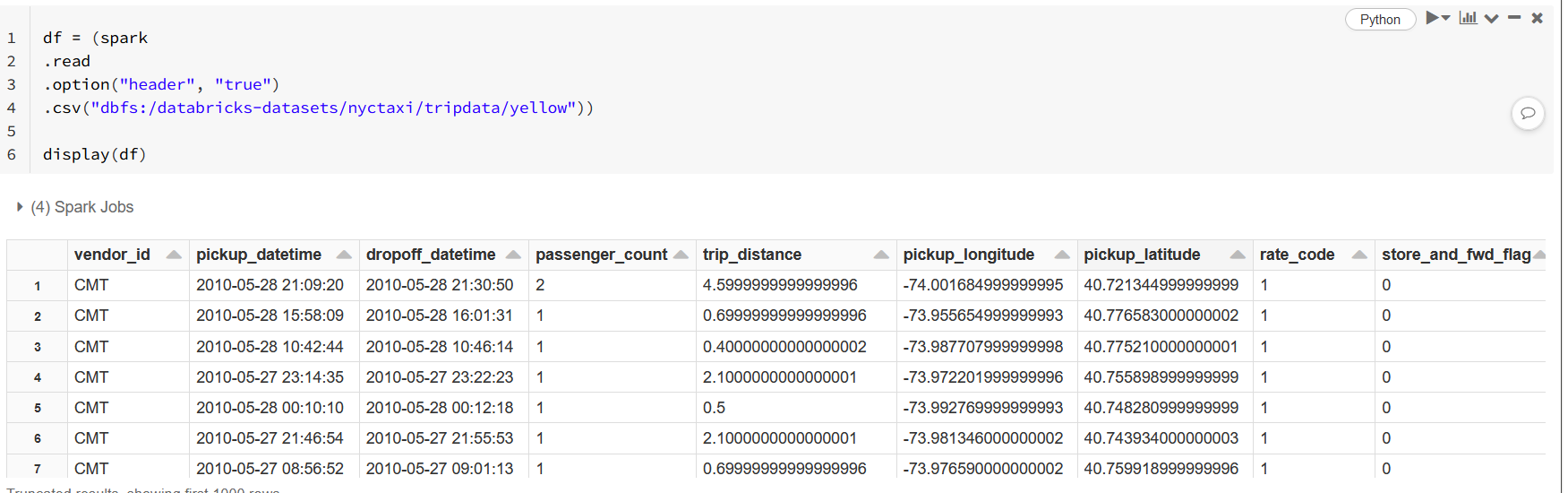
New Your Taxi data from your example is already included in your workspace as it is demo dataset.
It is enough to read "yellow" folder and it will read all csvs from there.
If you want to save it as a single file you can do .repartition(1).write.csv(destination_folder).save()

My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-18-2022 12:56 PM
Great!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-19-2022 07:45 AM
Unfortunately it seems that nytaxi is outdated. there is no records from 2021 and 2020 and 2019 is barely uncomplete
+-----------+------------------+
| 2010| 169001154|
| 2011| 176897208|
| 2015| 146112990|
| 2014| 165114361|
| 2013| 173179759|
| 2012| 178544324|
| 2009| 170896987|
| 2016| 131165043|
| 2017| 113496933|
| 2018| 102803387|
| 2041| 3|
| 2008| 585|
| 2001| 15|
| 2029| 6|
| 2002| 33|
| 2053| 2|
| 2003| 23|
| 2020| 438|
| 2019| 84397753|
| 2037| 1|
+-----------+------------------+
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-31-2022 04:04 AM
Thanks Kaniz, I already have the files. I was discussing about the best way to load them
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-31-2022 05:36 AM
Yes,
1) Downloaded the files using sh from here https://s3.amazonaws.com/nyc-tlc/trip+data/yellow_tripdata_<year>-<month>.csv to /mnt
2) Loaded a dataframe with the csv files
3) Stored as a partitioned table
I don´t know if this the best approach, but its working
Announcements





{kind=link}
Related Content
- Short Term Memory & Long Term Memory in Generative AI
- E2E MLOps Part 1: How to build and govern models with AutoML, MLflow, and Unity Catalog in Machine Learning
- Serverless egress - public internet access issues in Data Engineering
- Genie API List Conversations Incomplete in Generative AI
- AI BI Dashboard Table filtering in Warehousing & Analytics