Hey,
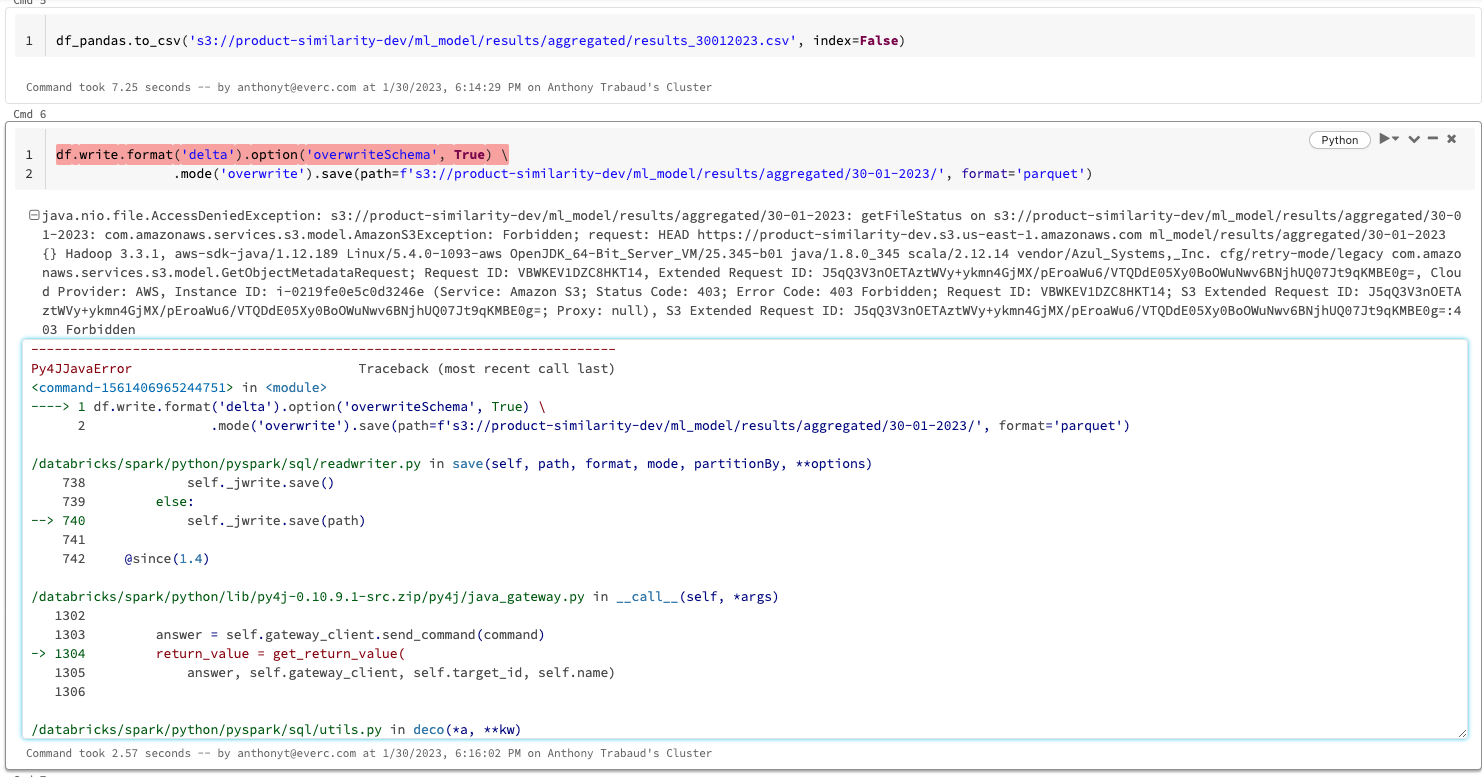
I have problem with access to s3 bucket using cross account bucket permission, i got the following error:
 Steps to repreduce:
Steps to repreduce:
- Checking the role that assoicated to ec2 instance:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*",
"s3-object-lambda:*"
],
"Resource": "*"
}
]
}
Also the bucket policy for specific s3 bucket is:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Databricks Access",
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::692503192357:user/product-similarity-s3-access",
"arn:aws:iam::692503192357:role/dev-databricks-role",
"arn:aws:iam::692503192357:role/dev-databricks-hy1-crossaccount"
]
},
"Action": [
"s3:DeleteObject",
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::product-similarity-dev",
"arn:aws:s3:::product-similarity-dev/*"
]
}
]
}
Please note that read access working as expected with spark but not write,
Also i can write to this s3 bucket using panda.
I would really appreciate your help







{kind=link}