Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Date field getting changed when reading from excel...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Date field getting changed when reading from excel file to dataframe in pyspark
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2022 10:40 PM
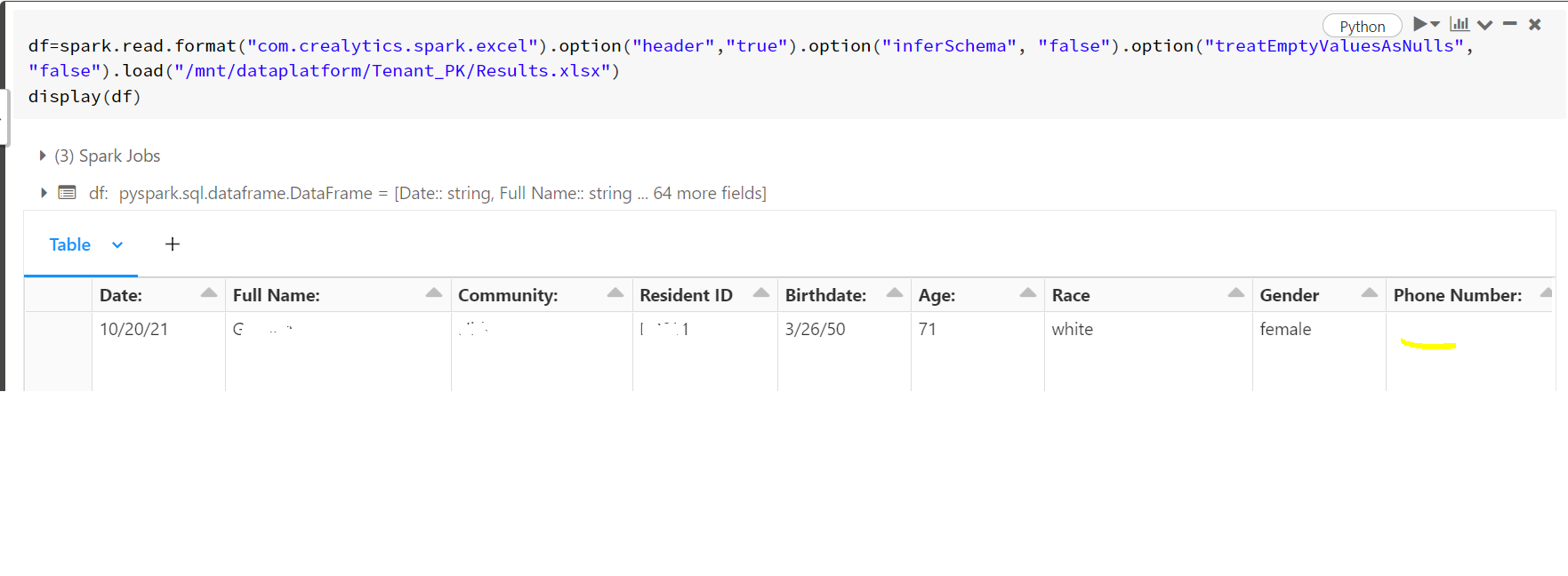
The date field is getting changed while reading data from source .xls file to the dataframe. In the source xl file all columns are strings but i am not sure why date column alone behaves differently
In Source file date is 1/24/1947.
In pyspark dataframe it is 1/24/47
Code used:
df=spark.read.format("com.crealytics.spark.excel").option("header","true").load("/mnt/dataplatform/Tenant_PK/Results.xlsx")
If I use option("inforscheme","true") the data coming properly , but I dont want use inforschema, Can any one suggest me any solution.
Thanks in advance
Labels:
- Labels:
-
Date Field


5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2022 10:52 PM
hi @Pradeep Namani ,
could you plz try to run below one. I hope so it will work without inferschema
df=spark.read.format("csv").option("header","true").load("/mnt/dataplatform/Tenant_PK/Results.xlsx")
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2022 11:12 PM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2022 11:13 PM
also u can refer below one
https://mayur-saparia7.medium.com/reading-excel-file-in-pyspark-databricks-notebook-c75a63181548
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-24-2022 03:08 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-24-2022 02:37 AM
how about using inferschema one single time to create a correct DF, then create a schema from the df-schema.
something like this f.e.
from pyspark.sql.types import StructType
# Save schema from the original DataFrame into json:
schema_json = df.schema.json()
# Restore schema from json:
import json
new_schema = StructType.fromJson(json.loads(schema_json))
Announcements





{kind=link}
{kind=link}
Related Content
- foreachPartition in Data Engineering
- Auto Loader with ignoreMissingFiles and useManagedFileEvents fails on Classic Compute in Data Engineering
- Autoloader inserts null rows in delta table while reading json file in Data Engineering
- OversizedAllocationException with transformWithStateInPandas in Data Engineering
- DLT Pipeline Error -key not found: all_info_dlt_cx_utils_cod resulting in a NoSuchElementException. in Data Engineering