Hi All,
I'm new to databricks and learning towards taking up Associate Engineer Certification.
While going through the section "Build Data Pipelines with Delta Live Tables".
I'm trying to implement Change Data Capture, but it is erroring out when executing the workflow.
'm not sure if my code is incorrect as It is similar to what we have in the course material. Please see details below and kindly let me know how to fix this.
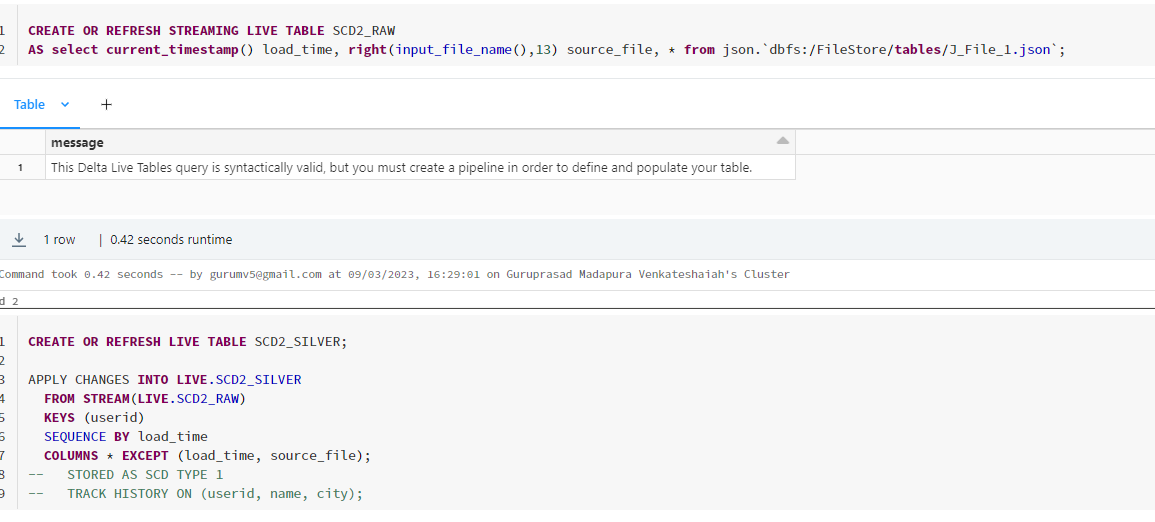
Screenshot of the Notebook used in the definition of the Pipeline.
Scroll down for the Code text and Error Text.

Code
CREATE OR REFRESH STREAMING LIVE TABLE SCD2_RAW
AS select current_timestamp() load_time, right(input_file_name(),13) source_file, * from json.`dbfs:/FileStore/tables/J_File_1.json`;
CREATE OR REFRESH STREAMING LIVE TABLE SCD2_SILVER;
APPLY CHANGES INTO LIVE.SCD2_SILVER
FROM STREAM(LIVE.SCD2_RAW)
KEYS (userid)
SEQUENCE BY load_time
COLUMNS * EXCEPT (load_time, source_file);
-- STORED AS SCD TYPE 1
-- TRACK HISTORY ON (userid, name, city);
Error
org.apache.spark.sql.AnalysisException: 'SCD2_RAW' is a streaming table, but 'SCD2_RAW' was not read as a stream. Either remove the STREAMING keyword after the CREATE clause or read the input as a stream rather than a table.
Thanks








{kind=link}
{kind=link}