Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- How can we sort the timeout issue in Databricks
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How can we sort the timeout issue in Databricks
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-25-2022 09:55 PM
we are creating a denorm table based on a JSON ingestion but the complex table is getting generated .when we try to deflatten the JSON rows it is taking for more than 5 hours and the error message is timeout error
is there any way that we could resolve this issue... Kindly help!!
Thanks
Labels:
- Labels:
-
Timeout


4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-25-2022 10:59 PM
did you enable the multiline option while reading the json, because that could be the cause?
See also here.
If you can, try with single-line format. Because then you can really leverage the parallel processing power of spark.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-26-2022 03:56 AM
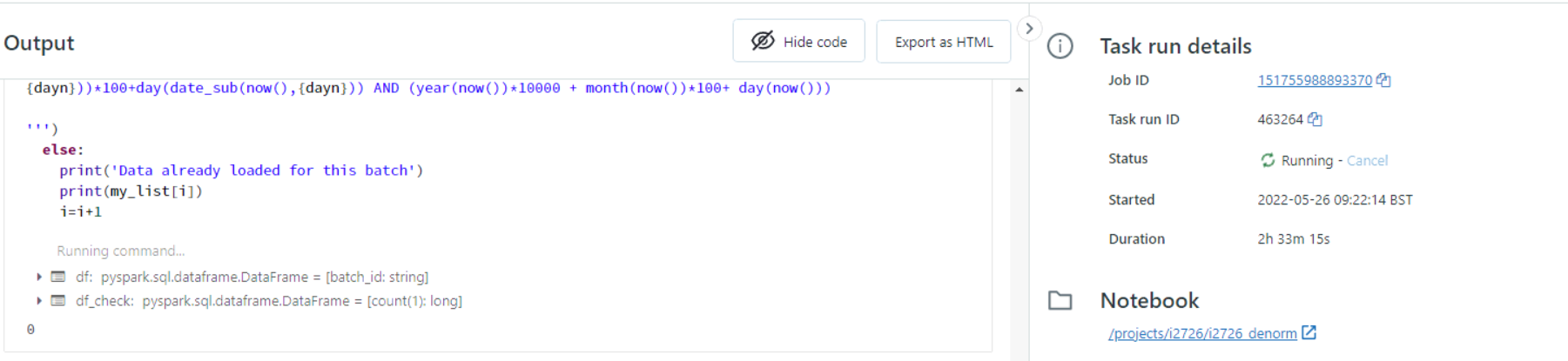
Still the notebook is running for 3 hours. below is the code that is running continously and also attached the error image

import json
i=0
df=spark.sql(f"""select distinct batch_id from sap_ingest_{env}.i2726_batch_control_delta_ns_tbl where raw_status='Running' and year*10000+month*100+day between year(date_sub(now(),{dayn}))*10000+month(date_sub(now(),{dayn}))*100+day(date_sub(now(),{dayn})) AND
(year(now())*10000 + month(now())*100+ day(now())) """)
my_list=[int(row.batch_id) for row in df.collect()]
while i < len(my_list):
#df_check = spark.sql(f'''select * from editrack_ingest_{env}.i1001_batch_control_ns_tbl where batch_id = {my_list[i]} ''')
#df_check.show()
#print(my_list[i])
#i=i+1
df_check = spark.sql(f'''select count(*) from sap_ingest_{env}.i2726_po_sto_ns_tbl where batch_id = {my_list[i]} and year*10000+month*100+day between year(date_sub(now(),{dayn}))*10000+month(date_sub(now(),{dayn}))*100+day(date_sub(now(),{dayn})) AND
(year(now())*10000 + month(now())*100+ day(now())) ''')
batchid_check=df_check.take(1)[0][0]
print(batchid_check)
if batchid_check==0:
spark.sql(f''' insert into table sap_ingest_{env}.i2726_po_sto_ns_tbl
partition (year,month,day)
select
y.batchRecordCount,
y.correlationId,
y.createdTimestamp,
y.envelopeVersion,
y.interfaceId ,
y.sequenceId,
y.interfaceName ,
y.messageId,
y.etag,
y.payloadKey,
y.payloadName,
y.payloadVersion,
y.securityClassification,
y.sourceApplicationName,
c.businessUnit,
c.countryOfOrigin ,
c.fobDate,
c.forwardingAgentDesc,
c.forwardingAgentId,
c.forwardingAgentDelPt,
c.incoTerms1,
c.incoTerms2 ,
c.initialOrderDate ,
c.initialOrderRef ,
c.invoicingPartyId,
c.orderingPartyId,
c.rtmPartyId,
c.reprocessorPartyId,
m.boxHangingInd,
m.changeIndicator,
m.deliveryTime,
d.amount ,
d.currency ,
d.type ,
p.custOrderNumber,
p.outloadDate,
p.collection_date,
p.celebration_date,
p.cust_message,
m.legacyProductId ,
m.lineItemId ,
m.netweight ,
m.orderUnit ,
m.productId ,
m.quantityPerOrderUnit ,
m.recStorageLocation ,
m.season,
m.totalQuantity ,
m.ultRecSapCode ,
m.ultimateReceivingLocationId ,
m.unitsOfWeight ,
m.contractID,
m.contractLineItem,
m.dispatchPriority,
m.updateReason,
m.knittedWoven,
m.year,
c.msgType ,
c.orderNumber ,
c.orderTypeSAP,
c.orderType ,
c.portOfLoading,
c.purchDept ,
c.purchaseOrderType ,
c.recSapCode ,
c.receivingLocationId ,
c.receivingLocationType ,
c.requestedDeliveryDate ,
c.sendSapCode,
c.sendingLocationId ,
c.sendingLocationType ,
c.shippingMethod ,
c.supplierFactoryDesc ,
c.supplierFactoryId ,
c.timestamp,
k.amount,
k.currency,
k.type,
x.load_timestamp,
x.batch_id ,
x.year ,
x.month ,
x.day
from sap_ingest_{env}.i2726_complex_ns_tbl as x
lateral view outer explode ((array(x.header))) explode_product as y
lateral view outer explode ((array(x.payload))) explode_product as c
lateral view outer explode(((c.totalPOValue))) explode_product as k
lateral view outer explode ((c.lineItems)) explode_product as po
lateral view outer explode ((po.itemValue)) explode_product as d
lateral view outer explode((x.payload.lineItems)) explode_product as m
lateral view outer explode((po.customer_order)) explode_product as p
where x.batch_id = "{my_list[i]}"
and x.year*10000+x.month*100+x.day between year(date_sub(now(),{dayn}))*10000+month(date_sub(now(),{dayn}))*100+day(date_sub(now(),{dayn})) AND (year(now())*10000 + month(now())*100+ day(now()))
''')
else:
print('Data already loaded for this batch')
print(my_list[i])
i=i+1
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-30-2022 01:10 AM
Why do you use a loop for executing the sql queries?
Spark will handle the parallel processing.
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-25-2022 09:33 AM
Hey @Raviteja Paluri
Hope all is well!
Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help.
Thanks!
Announcements





{kind=link}
Related Content
- Account does not exists error in Administration & Architecture
- DAB bundle deploy --force-lock creates duplicate jobs after Azure DevOps pipeline failure in Data Engineering
- Building a Metadata-Driven ETL Framework on Databricks in Data Engineering
- AutoML on Azure Databricks as of June 2026 in Machine Learning
- DeltaFileStatistics on a nested column (`created date.shipment`) cause filtering issues in Data Engineering