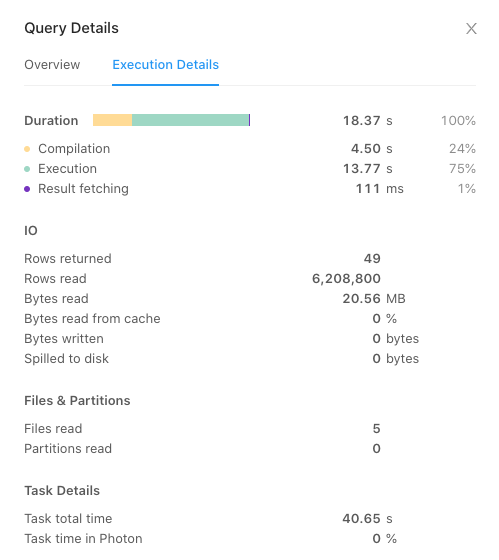
Databricks SQL endpoint has a query history section which provides additional information to debug / tune queries. One such metric under execution details is the number of files read.
For ETL/Data science workloads, you could use the Spark UI of the cluster and click on "Query Details" to get this info.







{kind=link}
{kind=link}