Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: How to perform a cross-check for data in multi...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-28-2022 04:30 PM
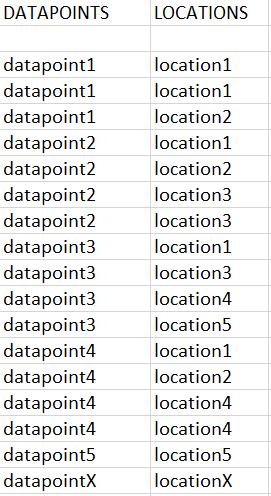
I am trying to check whether a certain datapoint exists in multiple locations.
This is what my table looks like:




1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-29-2022 01:48 AM
I think the example is too short to understand entirely (as in the source table, everything is distinct, and in the destination, the table count has a significant number) - please update both tables so the result will have a count based on the source.
Can datapoint have more than 2 locations?
I bet that the way is to create a copy of the dataframe and then join them together on a datapoint. Then, in the next step, filter, group, and count.
The kind of join used depends on the logic needed. For example, it can be join, inner join, but also intersect or intersectAll.
My blog: https://databrickster.medium.com/
10 REPLIES 10
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-28-2022 11:48 PM
you mean like an inner join on 2 dataframes?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-29-2022 06:40 PM
It might be. That is what I have been doing, but it has not worked for me. So I'm looking for other options that may be more beneficial for cross-checking multiple locations at once. However, I am still open to the suggestion if I can make it succeed.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-29-2022 01:48 AM
I think the example is too short to understand entirely (as in the source table, everything is distinct, and in the destination, the table count has a significant number) - please update both tables so the result will have a count based on the source.
Can datapoint have more than 2 locations?
I bet that the way is to create a copy of the dataframe and then join them together on a datapoint. Then, in the next step, filter, group, and count.
The kind of join used depends on the logic needed. For example, it can be join, inner join, but also intersect or intersectAll.
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-29-2022 06:50 PM
Here is a more accurate picture of my table:

Can you please clarify on what you mean by updating the count based on the source? I am trying to achieve the second table in a way that it only counts the datapoints if they go to both locations, and if there are duplicates, it only counts the datapoint ONCE rather than both times
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-29-2022 06:48 AM
Okay, so what you're trying to do (probably) is solved by running a join using the 'Datapoints' as the index on the same dataframe. It's probably not efficient, but you'd do something like:
df2 = df
df_joined = df.join(other=df2, on='Datapoints', how='Left').selectExpr('df.Location as `Location A`, 'df2.Location as `LocationB`')
df_joined.groupBy('Location A', 'Location B').agg(count('Location B').alias('Count'))I'm not sure this syntax works exactly as is, since I've never tried joining a table to itself.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-29-2022 06:52 PM
Can you please clarify what language this is? I am trying to perform the cross-check with SQL
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-30-2022 06:08 AM
@Viral Barot , It's Python. The SQL syntax can be inferred from the above. df.join is just SQL's JOIN. selectExpr just runs an SQL SELECT expression. groupBy is just an SQL GROUP BY. alias is exquivalent to using AS. etc.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-26-2022 02:58 PM
Thank you very much for your explanation
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-26-2022 02:58 PM
Hi,
Thank you very much for following up.
I no longer need assistance with this issue.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-27-2022 03:47 PM
Hi, I have marked an answer as best
Announcements





{kind=link}
{kind=link}
{kind=link}
Related Content
- Reading Spark UI: A Repeatable Guide to Finding Performance Bottlenecks in Data Engineering
- Improving Genie Space via text instructions in Generative AI
- Metric views joins in Data Engineering
- Can we add a column comments for a materialized view on Azure Databricks? in Data Engineering
- Building Resilient Data Pipelines: Databricks Autoloader with Safe Schema Evolution and Retry Logic in Data Engineering