I have 8gb of XML data loaded into different dataframes, there are two dataframes which has 24 lakh and 82 lakh data to be written to a 2 SQL server tables which is taking so 2 hrs and 5 hrs of time to write it.
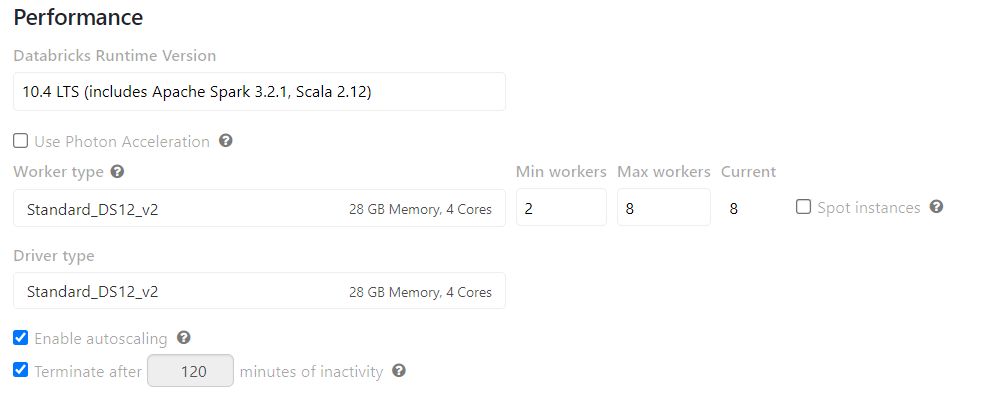
I am using the below cluster configuration

And the python code
df.write.format("jdbc").option("url", jdbcUrl).partitionBy("C_Code").mode("append").option("dbtable","staging.tablename").option("user", jdbcUsername).option("password", jdbcPassword).save()
please suggest me any other way to lower the execution time.







{kind=link}