Hi @shusharin_anton,
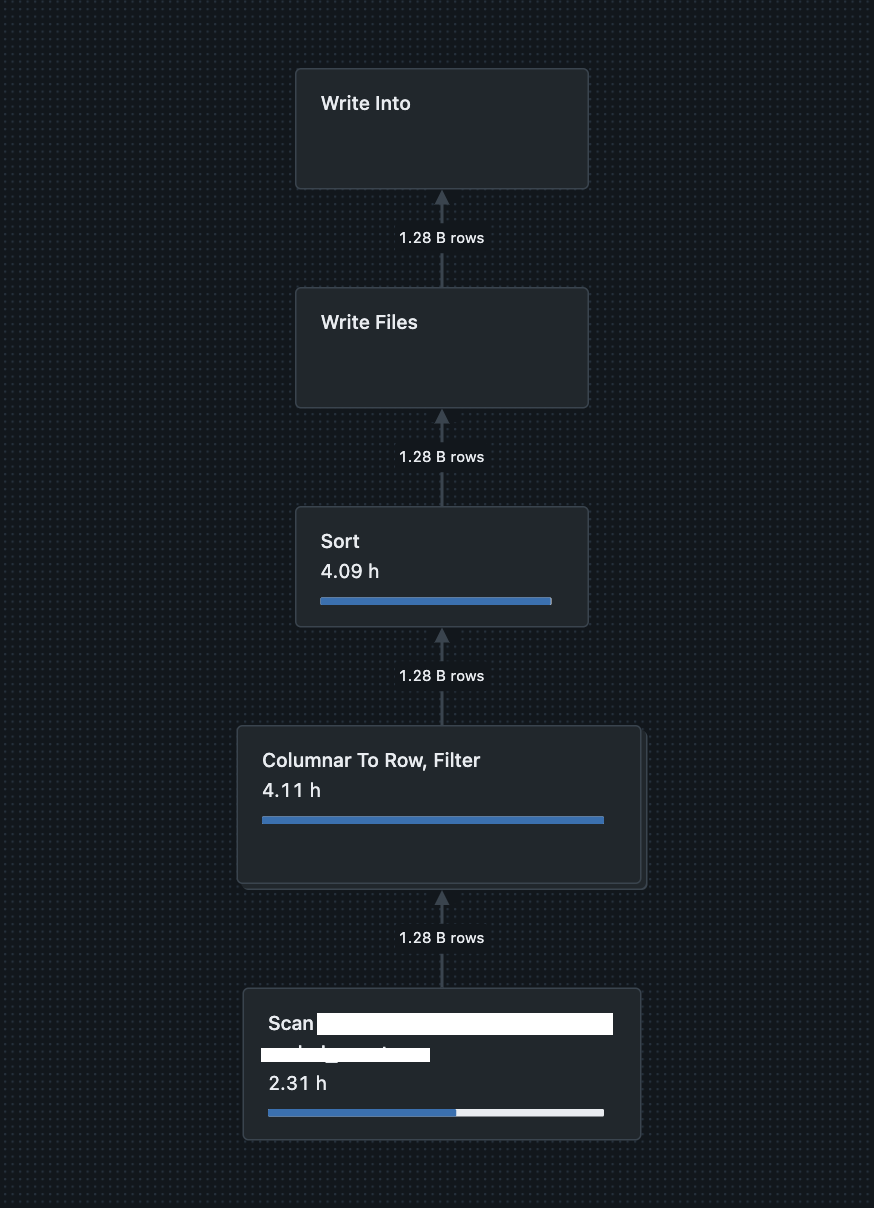
The sort and shuffle stages in your query profile are likely triggered by the need to redistribute and order the data based on the partition_date column. This behavior can be attributed to the way Spark handles data partitioning and sorting during query execution.
When you run an UPDATE statement, Spark may need to ensure that the data is correctly partitioned and sorted to apply the updates efficiently. This can involve shuffling data across different nodes to align with the partitioning scheme and then sorting it to maintain the correct order.
The sort operation on catalog.schema.table.partition_date ASC NULLS FIRST indicates that Spark is sorting the data based on the partition_date column in ascending order, placing null values first. This sorting is necessary to ensure that the updates are applied in the correct order, especially if the partition_date column is used for partitioning the table.
Disabling optimizeWrite might not affect this behavior because the sort and shuffle operations are fundamental to how Spark processes and optimizes queries involving partitioned tables. These operations are part of the query execution plan to ensure data consistency and efficient updates







{kind=link}