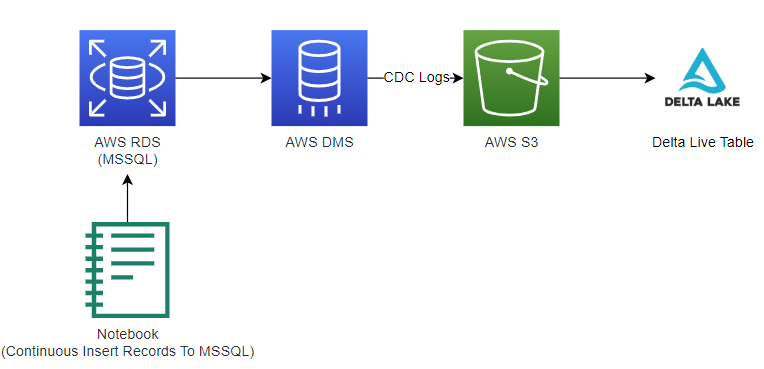
I have a dms task that processing the full-load and replication ongoing tasks
from source (MSSQL) to target (AWS S3)
then use delta lake to handle the CDC logs
I've a notebook that would insert data into mssql continuously (with id as primary key)
then delete some records from mssql directly
the delta lake would work perfectly when there's only insert records
but not the delete ones
it would have some random records being deleted that apply to delta lake
for example.
i first insert 10,000 records
the delta lake apply the insert action perfectly
but when i delete some records (id > 8000) from MSSQL and count the records in delta lake
it would not apply correctly (getting count result > 8000)
wonder if any step i missed
thanks
the diagram
![204293406-01bf6cc1-bb6f-42bb-9bfe-e9b1f5135ae9[1]](/t5/image/serverpage/image-id/1103i5E2E130C9E462F86/image-size/large?v=v2&px=999 "204293406-01bf6cc1-bb6f-42bb-9bfe-e9b1f5135ae9[1]")
Code
1.Continuous insert job
# Databricks notebook source
"""
This script is used to load data to sql server database.
"""
# COMMAND ----------
# MAGIC %pip install Faker
# COMMAND ----------
from faker import Faker
from pyspark.sql import SparkSession, functions, DataFrame
from pyspark.sql.types import StructField, StructType, DecimalType
from typing import List
# COMMAND ----------
spark = SparkSession.builder. \
appName("ExamplePySparkSubmitTask"). \
config("spark.databricks.hive.metastore.glueCatalog.enabled", "true"). \
enableHiveSupport(). \
getOrCreate()
# COMMAND ----------
faker = Faker()
# COMMAND ----------
def create_sample_profiles(
_faker: Faker()
):
"""
This function is to create sample profiles
"""
profiles = [_faker.profile() for _ in range(1000)]
return profiles
# COMMAND ----------
def read_profiles_as_dataframe(
_spark: SparkSession,
_profiles: List[dict]
):
"""
This function is to read profiles as dataframe
"""
df = _spark \
.createDataFrame(_profiles)
return df
# COMMAND ----------
def process_data(
_df: DataFrame,
_count: int
):
"""
This function is to process data with requirements
"""
processed_df = _df \
.coalesce(1) \
.withColumn('id', (1000 * _count) + (functions.monotonically_increasing_id() +1) ) \
.withColumn('age', functions.round(functions.rand() * 130)) \
.withColumn('latitude', functions.col('current_location._1')) \
.withColumn('longitude', functions.col('current_location._2')) \
.withColumn('website', functions.concat_ws(',', 'website')) \
.drop('current_location')
return processed_df
# COMMAND ----------
def write_dataframe_to_sql_server(
_df: DataFrame
):
"""
This function is to write dataframe to sql server
"""
jdbc_options = {
"url": '<URL>',
"user": 'admin',
"password": '<Password>',
"dbtable": 'profiles'
}
_df \
.write \
.format('jdbc') \
.options(**jdbc_options) \
.mode('append') \
.save()
# COMMAND ----------
def main(
_count: int
):
"""
This is main function
"""
try:
profiles = create_sample_profiles(
_faker=faker
)
df = read_profiles_as_dataframe(
_spark=spark,
_profiles=profiles
)
processed_df = process_data(
_df=df,
_count=_count
)
write_dataframe_to_sql_server(
_df=processed_df
)
except:
raise
# COMMAND ----------
if __name__ == '__main__':
main(0)
# COMMAND ----------
import time
count = 0
while(count < 5):
print(count)
main(
_count=count
)
count += 1
# COMMAND ----------
2.DLT Job
# Databricks notebook source
"""
This script is to process delta lake
"""
# COMMAND ----------
import dlt
from pyspark.sql.functions import col, expr
# COMMAND ----------
@dlt.table(
name="profiles_changes",
temporary=True
)
# @dlt.expect("valid age", "age > 0 and age <= 100")
def profiles_changes():
schema = 'Op STRING, cdc_load_timestamp TIMESTAMP, address STRING, birthdate DATE, company STRING, job STRING, mail STRING, name STRING, residence STRING, ssn STRING, username STRING, website STRING, id LONG, age DOUBLE, latitude Decimal(38,18), longitude Decimal(38,18)'
return spark \
.readStream \
.format('cloudFiles') \
.option("cloudFiles.format", "parquet") \
.option("cloudFiles.schemaHints", schema) \
.schema(schema) \
.load('s3://<replication_bucket>/sql_server_repication/dbo/profiles/*/*/*/*/*.parquet')
# COMMAND ----------
dlt.create_streaming_live_table(
name="profiles",
path="s3://<staging_bucket>/staging/profiles/"
)
# COMMAND ----------
dlt.apply_changes(
target = "profiles",
source = "profiles_changes",
keys = ["id"],
sequence_by = col("cdc_load_timestamp"),
apply_as_deletes = expr("Op = 'D'"),
apply_as_truncates = expr("Op = 'T'"),
except_column_list = ["Op", "cdc_load_timestamp"],
stored_as_scd_type = 1
)
# Observed results
The delta lake not apply the CDC logs correctly (by count in mssql & delta lake)
# Expected results
The delta lake should apply the CDC logs correctly (by count in mssql & delta lake)
# Environment information
- Delta Lake version: 11.3
- Spark version: 3.3.0
- Scala version: 2.12.14







{kind=link}