Hey all,
Is anyone else experiencing major friction when using LangChain within Databricks?
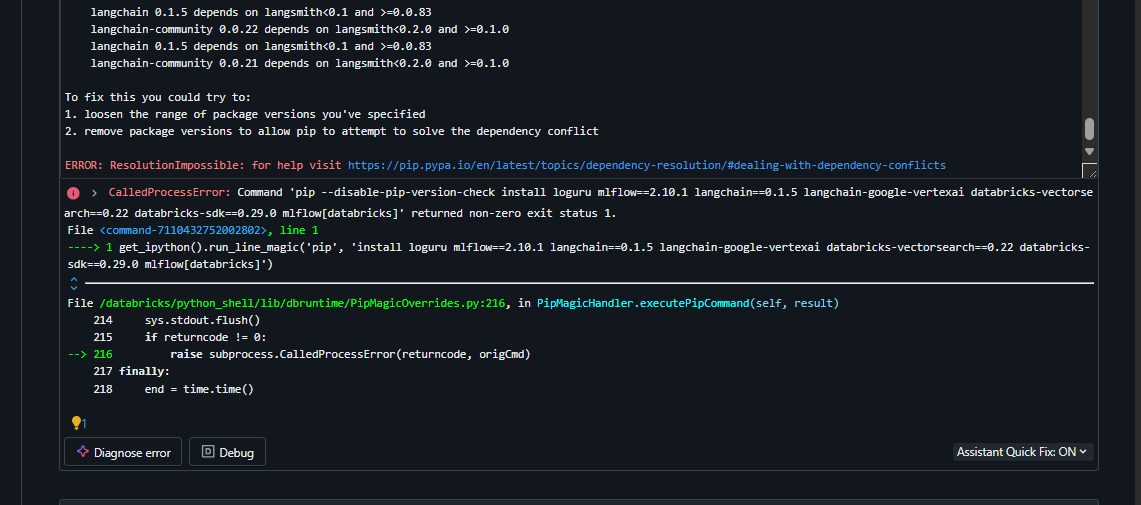
Even after carefully pinning versions like:
%pip install \
loguru \
mlflow==2.10.1 \
langchain==0.1.5 \
langchain-google-vertexai \
databricks-vectorsearch==0.22 \
databricks-sdk==0.29.0 \
mlflow[databricks]
...and calling dbutils.library.restartPython() right after it still behaves inconsistently. Sometimes packages silently fail, other times langchain breaks due to dependency conflicts (often with pydantic, openai, or Google SDKs). And this is on a standard single-user cluster, nothing exotic.
It feels like a bit of a mess trying to use LangChain at scale.
Is there an official best practice here for using LangChain (or even LangChain derivatives like LangGraph) in Databricks? Are people resorting to Docker containers, separate virtual environments, or avoiding LangChain altogether in production workflows?
Would love to hear how others are navigating this — or if anyone from Databricks has a clear solution.
Thanks in advance!







{kind=link}