Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Performance Tuning Best Practices
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Performance Tuning Best Practices
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-22-2022 11:54 PM
Recommendations for performance tuning best practices on Databricks
We recommend also checking out this article from my colleague @Franco Patano on best practices for performance tuning on Databricks.
Performance tuning your workloads is an important step to take before putting your project into production to ensure you are getting the best performance and the lowest cost to help meet you save money and meet your SLAs.
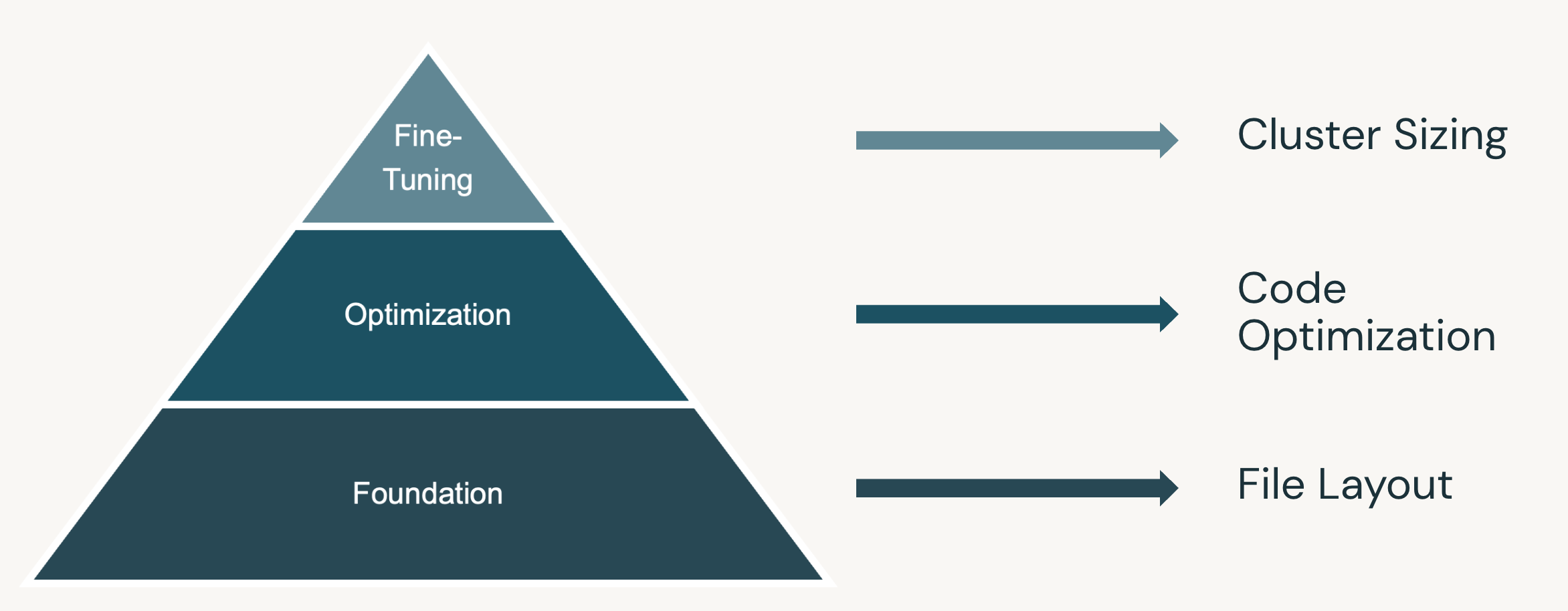
When tuning on Databricks, it is important to follow the the framework illustrated in the diagram below:
- First, focus on the foundation, the file layout. Efficient file layout is the most important focus for any MPP system to 1) reduce the overhead from too many small files, 2) reduce or remove data skew, and 3) reduce the amount of data you are scanning and reading into the MPP system.
- Once you have optimized file layout, then you can optimize your code base to remove potential code bottlenecks.
- Finally, once you have optimized the files and the code, then you can fine-tune your workload by choosing the optimal cluster configuration for your workload.

Continued below
Labels:
4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-22-2022 11:54 PM
File Layout Optimization - tips for efficient file layout
- Leverage Delta Lake for your workloads to unlock performance capabilities such as Z-Order Clustering.
- Use Z-Order (AWS | Azure | GCP) on high cardinality columns frequently used in filters. Z-Order works similar to indexing and colocates related data to dramatically reduce the amount of data that needs to be read, which can result in dramatic performance improvements.
- Use ANALYZE TABLE COMPUTE STATISTICS (AWS | Azure | GCP) to collect column statistics for columns frequently used in joins and filters. These column statistics are used by the Databricks cost-based optimizer and Adaptive Query Execution to ensure the most optimal query plan is chosen for your workload.
- Use PARTITIONED BY (AWS | Azure | GCP) to partition your largest tables by low cardinality columns frequently used in filters (this is often the date column). We do not recommend partitioning tables less than 1 TB, as this may lead to over-partitioning your dataset. With DBR 11.2+, Ingestion Time Clustering will preserve the natural date order of your ingested data, eliminating the need for partitioning or Z-ordering on tables under 1 TB and resulting in great out-of-the-box performance.
- For workloads with frequent MERGE and write operations, your workload may benefit from Autotune based on workload (AWS | Azure | GCP) rather than the default based on table size.
- Your workload may benefit from increased parallelism by setting the spark shuffle partitions to auto (AWS | Azure | GCP)
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-22-2022 11:55 PM
Code Optimization - advice to avoid code bottlenecks
- Avoid operations that result in Actions such as print, collect, and count in production pipelines. These operations force Spark to execute right away rather than pipelining multiple operations and determining the best query plan.
- Avoid using RDDs whenever possible. The RDD API does not benefit from the performance optimizations of the Catalyst optimizer and many of the Databricks built-in runtime performance optimizations.
- Avoid single-threaded Python or R workloads on multi-node clusters as these will result in only the driver node being utilized while the worker nodes remain idle. This includes using .toPandas().
- For working with smaller datasets and single-threaded operations, we highly recommend using single node clusters (AWS | Azure | GCP) for cost optimization.
- For working with large scale datasets, we recommend leveraging built-in spark functions as much as possible. When this is not possible we recommend using Pandas UDFs (AWS | Azure | GCP) to distribute existing python code using Spark. Alternatively, you can also leverage the Pandas API on Spark (AWS | Azure | GCP) which allows you to leverage 90% of the python Pandas functions while distributing the processing with Spark for scalability.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-22-2022 11:55 PM
Cluster Optimization - how to choose the right cluster for your workload
- Choose the optimal instance/VM type for your workloads. Here are the general recommendations:
- Storage-optimized instances work best for large batch jobs and ad-hoc analytics
- Compute-optimized for machine learning and structured streaming workloads
- Memory-optimized for memory-intensive workloads
- GPU-optimized for deep learning workloads
- Enable Photon (AWS | Azure | GCP) on your clusters for up to 80% TCO savings on analytics workloads. Photon is enabled by default for Databricks SQL Warehouses.
- Enable auto-scaling for Databricks Clusters (AWS | Azure | GCP), DLT Clusters (AWS | Azure | GCP), SQL Warehouses (AWS | Azure | GCP) to automatically add and remove nodes based on workloads.
- Enable the latest LTS Databricks Runtime (AWS | Azure | GCP). Databricks Runtimes correspond with the latest advancements in Spark and Databricks including the latest performance enhancements. Databricks LTS runtimes are supported for a minimum of 2 years.
- Tune cluster sizes based on your SLAs and cluster utilization. We recommend testing out several cluster sizes in a proof of concept to find the cluster configuration that gives you the best price performance while meeting your SLAs and expected scalability.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-22-2022 11:55 PM
Let us know in the comments if you have any other performance tuning tips & tricks
Announcements





{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Optimal Cluster Configuration for Training on Billion-Row Datasets in Machine Learning
- need to ingest millions of csv files from aws s3 in Data Engineering
- DLT: Autoloader Perf in Data Engineering
- Unable to perform VACUUM on Delta table in Data Engineering
- How to include additional feature columns in Databricks AutoML Forecast? in Machine Learning