I am attempting to stream JSON endpoint responses from an s3 bucket into a spark DLT. I have been very successful in this practice previously, but the difference this time is that I am storing the responses from multiple endpoints in the same s3 bucket, whereas before it has been a single endpoint response in a single bucket.
Setting The Scene
I am making GET requests to 9 different Season Endpoints, each for a different Sports League. The endpoints return a list of Seasons for the given Sports League. I decided to store them all in the same s3 bucket because the endpoint responses are structured almost identically.
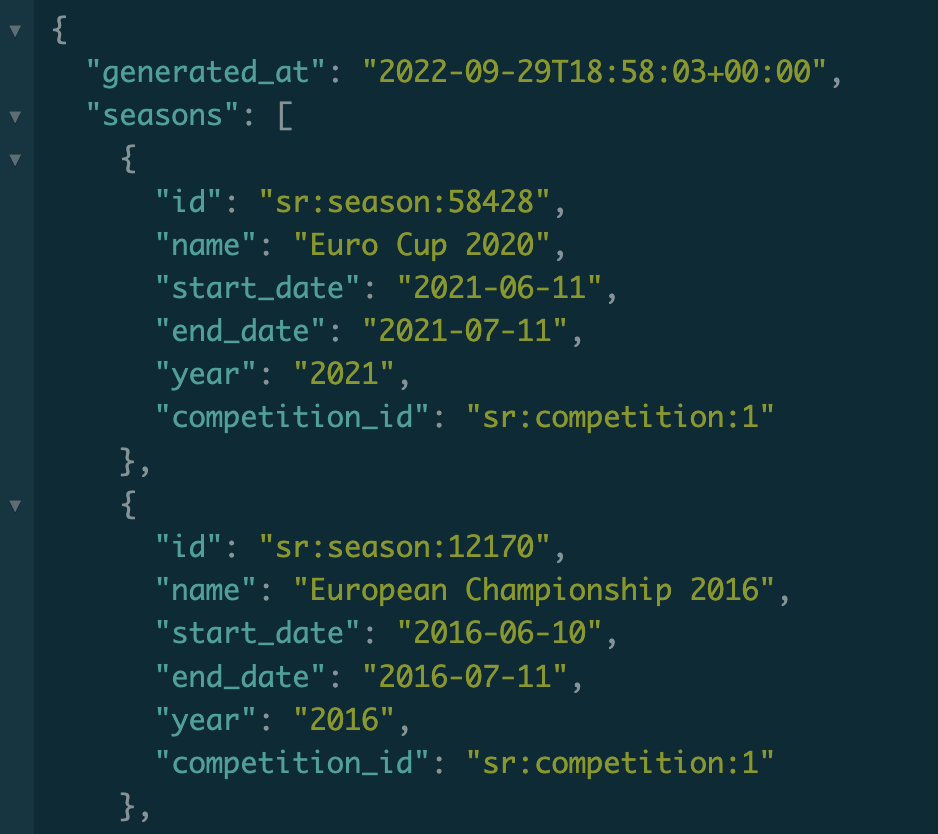
8/9 of the endpoints return a response structured like so:
Giving a League and list of Seasons

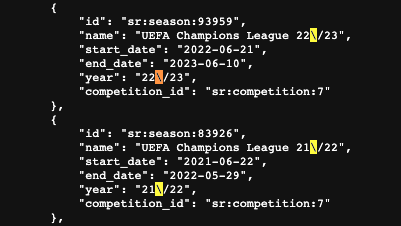
The 9th endpoint is for Soccer Seasons, which is structured slightly differently but it also returns a list of Seasons.

Key endpoint differences:
- 8/9 endpoints give a League object, Season.Type, and Season.Status
- The 9th (Soccer) endpoint does NOT have a League object, Season.Type, nor Season.Status
- It additionally provides a Season.Competitor_Id
- It is also important to note, not all 8/9 endpoint responses are exactly the same and there is some variation in the provided Season fields.
The Issue:
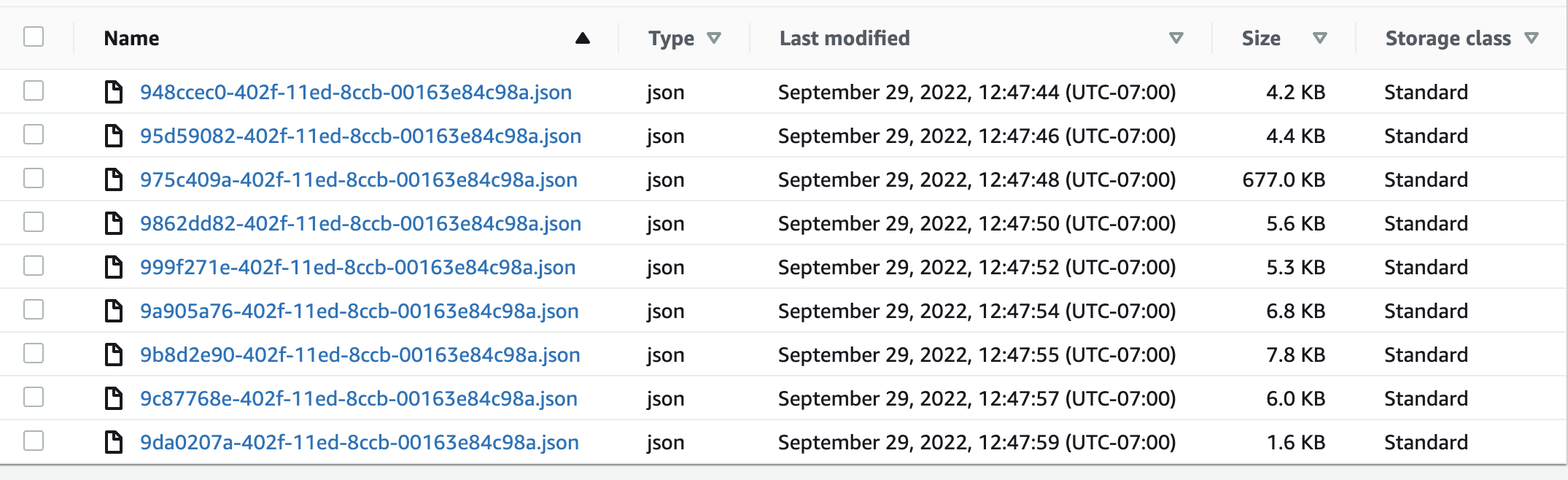
When Spark Streaming from the s3 bucket, it says there are thousands of JSON files when there are only 9.
Here you can see all 9 in the bucket. Notice Soccer is the largest file as well.

However, when displaying the streaming spark data frame of the s3 bucket it shows there are thousands of null soccer JSON files while also correctly displaying the other 8 sports as having only 1 JSON file.
I suspect that the soccer endpoint response file is being auto-exploded into thousands of files. This would explain why the Seasons column for soccer is null because it has already exploded and now contains other fields.
Any guidance would be appreciated and if I can be any more clear please let me know.
Thanks in advance!






{kind=link}
{kind=link}
{kind=link}
{kind=link}