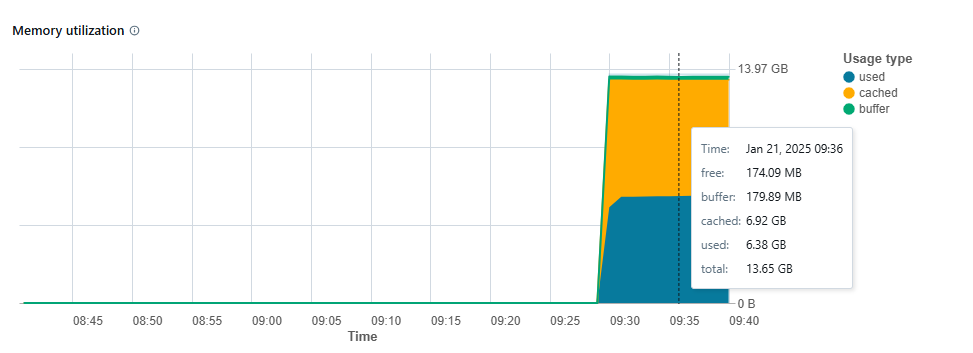
In my team we have a very high memory usage even when the cluster has just been started and nothing has been run yet. Additionally, memory usage never drops to lower levels - total used memory always fluctuates around 14GB.
- Where is this memory usage coming from? Is it possible to see more detailed information about what processes exactly are consuming our memory?
- We are trying to figure out the most optimal way of allocating memory to our executors. Assuming that we have 14GB Memory available on each worker node and there is one executor per worker node - what should be the total memory available on executor? Currently our spark.executor.memory is set to 7GB, but we are wondering if we could increase it a bit, but we are not sure how much memory should be left for Databricks processes (looking at the chart a lot..)
I would appreciate your help!







{kind=link}